在人工智能领域,注意力机制(Attention Mechanism)一直是提升模型性能的关键技术之一。DeepSeek近日开源的FlashMLA解码内核,基于其创新的多头潜在注意力机制(Multi-head Latent Attention, MLA),为AI推理效率带来了革命性突破。

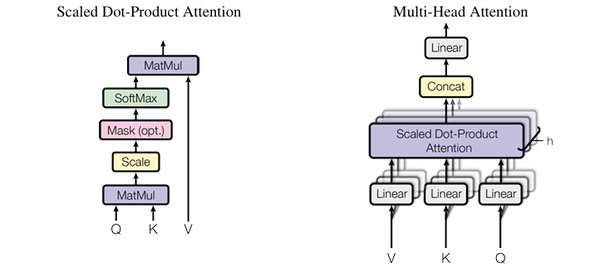
什么是多头潜在注意力机制(MLA)?
多头潜在注意力机制(MLA)是DeepSeek提出的一种低秩注意力机制,与传统多头注意力机制(Multi-head Attention)不同,MLA通过压缩注意力矩阵,显著减少了参与运算的参数数量。这种设计不仅降低了计算和存储成本,还将显存占用降到了其他大模型的5%-13%,同时保持了模型的高性能。
![]()
![]()
FlashMLA的技术突破
FlashMLA是DeepSeek针对Hopper GPU优化的高效MLA解码内核,专为处理可变长度序列而设计。其主要技术突破包括:
-
BF16支持:提供更高效的数值计算能力,减少计算精度损失,同时优化存储带宽使用率。
-
分页KV缓存:采用高效的分块存储策略,减少长序列推理时的显存占用,提高缓存命中率。
-
极致性能优化:在H800 GPU上,FlashMLA通过优化访存和计算路径,达到了3000GB/s内存带宽和580TFLOPS的计算能力,最大化利用GPU资源,减少推理延迟。

动态序列优化的意义
在实际应用中,用户输入的序列长度往往不规则,例如长上下文对话或超长PDF文档。FlashMLA通过动态调度和内存优化,支持“动态序列”场景,确保在处理不同长度序列时仍能保持高效。这种设计特别适用于高性能AI任务,进一步突破GPU算力瓶颈,降低成本。
开源模式加速AI行业发展
DeepSeek的开源策略不仅推动了技术创新,还为整个AI行业带来了深远影响。FlashMLA的开源让更多开发者能够利用这一高效解码内核,加速AI应用的开发与部署。业内专家认为,DeepSeek的开源模式为AI行业开辟了新的路径,其低秩注意力机制和GPU优化技术将成为未来AI发展的重要方向。
行业影响与未来展望
FlashMLA的开源标志着DeepSeek在AI技术领域的领先地位。通过持续开源和透明分享,DeepSeek不仅推动了行业技术进步,还为AI普及和创新提供了强大动力。未来,随着更多开源项目的发布,DeepSeek有望进一步推动AI生态的繁荣发展,为全球开发者带来更多技术红利。
DeepSeek的开源精神和创新技术,正在掀起AI行业的“巨浪”,而FlashMLA只是这场变革的开始。









