近年来,DeepSeek-V3/R1模型因其强大的性能和广泛的应用场景迅速走红,甚至引发了API服务的低价内卷。然而,如何在这一浪潮中脱颖而出,构建高质量、定制化的私有模型,成为许多企业关注的焦点。开源模型为这一需求提供了“巨人的肩膀”,而Colossal-AI发布的开源大模型后训练工具箱,则为低成本微调和强化学习提供了强大的支持。

开源模型的“巨人肩膀”
DeepSeek-V3/R1满血版拥有高达6710亿参数,其强大的计算能力和推理性能使其成为AI领域的热门选择。然而,直接使用原始模型或API服务往往难以满足企业的特定需求。通过后训练(post-training)结合专业领域数据,企业可以低成本打造高质量的私有模型,从而提升业务竞争力和价值。
Colossal-AI:开源大模型后训练工具箱
Colossal-AI发布的开源大模型后训练工具箱,为开发者提供了丰富的工具链和灵活的配置选项,助力低成本微调和强化学习。其主要特点包括:
-
低成本监督微调:支持DeepSeek-V3/R1满血版的LoRA低成本微调,最低硬件要求降低近10倍。
-
强化学习工具链:提供完整的强化学习工具链,包括PPO、GRPO、DPO、SimPO等。
-
硬件兼容性:兼容英伟达GPU、华为昇腾NPU等多种硬件,支持混合精度训练和gradient checkpoint等训练加速技术。
-
灵活配置:支持自定义奖励函数、损失函数,提供灵活的并行策略配置接口,包括数据并行、模型并行、专家并行、ZeRO和Offload等。

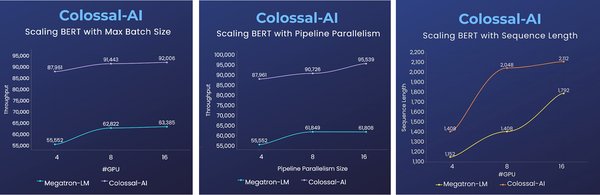
低成本微调实战指南
对于预算有限的企业,Colossal-AI提供了详细的低成本微调实战指南。以下是关键步骤:
-
数据集准备:使用JSONL格式的文件作为输入数据集,兼容Huggingface chat template,支持自定义system prompt。
-
模型权重准备:使用BF16权重进行微调,支持通过GPU或NPU转换权重。
-
一键启动脚本:使用Colossal-AI提供的一键启动脚本,快速完成微调任务。
-
LoRA优化:通过LoRA等优化技术,大幅降低硬件资源消耗,支持CPU offload进一步降低成本。
强化学习微调:GRPO算法验证
Colossal-AI团队验证并实现了DeepSeek论文中的GRPO算法及verifiable reward,使用Qwen2.5-3B-Base模型进行了实验。奖励设计如下:
-
奖励 = 0,如果格式是错误的;
-
奖励 = 1,如果格式是正确的但是结果是错误的;
-
奖励 = 10,如果格式与结果都是正确的。
通过灵活的奖励函数模板,用户可以根据具体需求设计自己的奖励函数体系。
结语
DeepSeek-V3/R1模型的火爆为AI领域带来了新的机遇,而开源模型和Colossal-AI的后训练工具箱则为企业提供了低成本构建高质量私有模型的可能。通过灵活的微调和强化学习工具链,企业可以充分利用“巨人的肩膀”,在激烈的市场竞争中脱颖而出。











