
1. AIGC的概念与技术原理
AIGC(AI Generated Content)是指利用人工智能技术生成内容,涵盖文字、图像、视频、音频、游戏和虚拟人等多个领域。AIGC的核心技术包括GAN(生成对抗网络)、Transformer模型、Diffusion模型和CLIP(对比语言-图像预训练模型)等。这些技术通过模拟人类的创作过程,实现了从简单到复杂的内容生成。
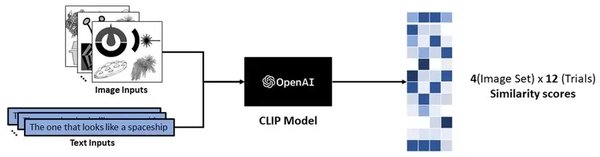
2. CLIP模型在多模态生成中的关键作用
CLIP模型是OpenAI开发的一种多模态模型,能够将图像和文本进行对比学习,从而实现跨模态的理解和生成。CLIP的核心优势在于其能够将图像和文本映射到同一语义空间,使得模型能够根据文本描述生成图像,或者根据图像生成相应的文本描述。
2.1 CLIP的工作原理
CLIP通过对比学习的方式,将图像和文本编码到同一高维空间中。具体来说,CLIP使用两个独立的编码器分别处理图像和文本,然后通过对比损失函数来优化这两个编码器的输出,使得相似的图像和文本在语义空间中距离更近。
2.2 CLIP的应用场景
CLIP在多个领域展现了强大的应用潜力,包括图像生成、图像分类、视觉问答(VQA)和图文匹配等。例如,在图像生成任务中,CLIP可以根据文本描述生成高质量的图像,极大地提升了生成图像的语义一致性和多样性。
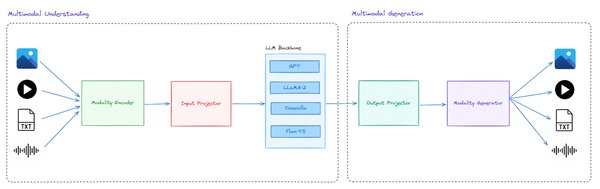
3. 多模态生成模型的架构与优化
多模态生成模型如Janus-Pro,通过解耦视觉编码的设计理念,将多模态理解与视觉生成任务分离开来,以充分发挥各自优势。Janus-Pro的核心创新在于将视觉编码过程分为两个独立的路径,从而解决传统统一编码中“理解”和“生成”任务之间的冲突。
3.1 理解编码器与生成编码器
Janus-Pro的理解编码器基于SigLIP视觉编码器,能够从图像中提取高维语义特征,支持多模态理解任务。生成编码器则使用VQ Tokenizer将图像转换为离散的ID序列,支持文本到图像的生成任务。这种解耦设计使得模型在多模态任务中表现更为出色。
3.2 训练策略的优化
Janus-Pro在训练策略上进行了显著优化,包括延长ImageNet数据上的训练步数、取消基于ImageNet分类提示的训练部分,以及调整多模态理解数据与文本到图像数据的比例。这些优化措施提升了模型的训练效率和性能表现。
4. AIGC的未来展望
随着AI技术的不断进步,AIGC在内容创作领域的应用将更加广泛。未来,AIGC有望在以下几个方面取得突破:
-
更高质量的内容生成:通过优化模型架构和训练策略,AIGC将能够生成更加逼真和多样化的内容。
-
跨模态理解与生成:多模态模型如CLIP和Janus-Pro将进一步增强跨模态的理解与生成能力,实现更加复杂的内容创作。
-
应用场景的拓展:AIGC将在虚拟现实、增强现实和元宇宙等领域发挥更大的作用,推动数字内容创作的革新。
AIGC技术的发展将为内容创作带来革命性的变化,而CLIP和多模态生成模型将在这一进程中扮演关键角色。










