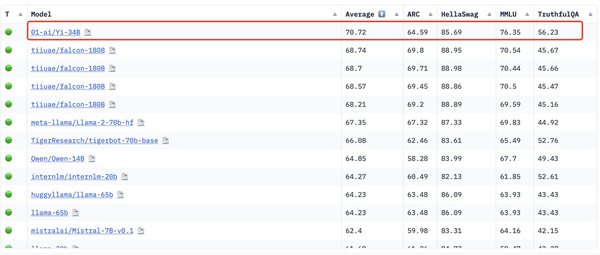
Yi-34B:国产开源大模型的里程碑
零一万物,由李开复创立的AI公司,近日发布了开源大模型Yi-34B。这一模型在Hugging Face和C-Eval的评测中取得了多项国际最佳性能指标,成为首个登顶Hugging Face全球开源模型排行榜的国产模型。这一成就不仅标志着中国在AI领域的技术突破,也为全球开源社区注入了新的活力。
Yi-34B的成功并非偶然。其背后是零一万物团队对AI技术的深刻理解和不懈追求。通过开源,Yi-34B不仅为全球开发者提供了强大的工具,也为中国AI技术的国际化铺平了道路。


多模态数据集PIN-14M的启示
在探讨Yi-34B的未来发展时,我们不得不提到多模态数据集PIN-14M。这一由M-A-P团队和2077AI开源社区共同构建的数据集,旨在解决现有多模态数据集在训练大型多模态模型(LMM)时存在的感知和推理错误问题。
PIN-14M通过结合Markdown文件和图像,采用知识密集型、可扩展和支持多种训练策略的设计理念,极大地增强了模型学习复杂任务的能力。其核心原则包括:
-
知识密集型:每个样本包含文本和图像的紧密结合,通过Markdown格式文档和全局图像表达多模态信息。
-
可扩展性:PIN数据集通过统一的格式兼容并转换现有的多模态数据集,支持更大规模的数据集构建。
-
支持多种训练策略:PIN格式支持图像-文本配对、交错训练等多种训练策略,提升模型推理能力。


Yi-34B与多模态未来的结合
Yi-34B的成功为多模态模型的发展提供了新的可能性。结合PIN-14M数据集的前沿技术,Yi-34B有望在以下领域取得突破:
-
复杂视觉数据解释:通过PIN-14M的结构化数据,Yi-34B可以更好地理解和解释复杂视觉信息。
-
多模态关系推断:PIN-14M的交错信息布局有助于Yi-34B在多模态关系推断方面取得进展。
-
科学文献分析:PIN-14M丰富的科学和网络内容为Yi-34B在科学文献分析等高阶任务中提供了强有力的支持。
展望国产AI的未来
Yi-34B的成功和PIN-14M的前沿发展,共同描绘了国产AI的美好未来。通过不断的技术创新和开源合作,中国AI技术将在全球舞台上发挥越来越重要的作用。零一万物和M-A-P团队的努力,不仅推动了AI技术的发展,也为全球AI社区提供了宝贵的资源。
在未来,随着数据集的进一步扩展和优化,Yi-34B和PIN-14M有望成为多模态模型训练的核心基础,推动人工智能在更多复杂任务中的应用。国产AI的崛起,不仅是技术的胜利,更是中国在全球科技领域影响力的体现。







