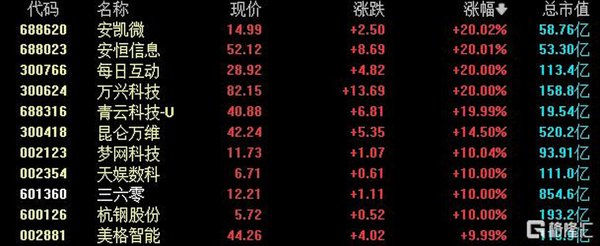
今年春节假期,DeepSeek大模型成为最火爆的话题之一。多家上市公司宣布接入DeepSeek大模型,导致相关概念股在A股市场涨停。DeepSeek是杭州深度求索人工智能基础技术研究有限公司开发的大模型,其V3和R1版本发布后受到广泛认可。上市公司接入DeepSeek大模型后,预计将带来业务提升和功能优化。

MoE技术的创新应用
DeepSeek的核心技术之一是MoE(Mixture of Experts)技术。MoE通过将巨大模型分割成多个专家(Expert),根据输入数据动态选择需要的专家进行计算,从而显著降低计算成本。这种技术不仅提高了模型的效率,还大幅减少了资源消耗。DeepSeek在V3版本中首次引入MoE技术,并在R1版本中进一步优化,使其在性能和成本之间达到了最佳平衡。


模型架构与训练方法的突破
DeepSeek在模型架构和训练方法上也有显著创新。其采用的MLA(Memory-Level Attention)技术通过压缩输入数据,将计算所需的存储容量减半,从而在硬件资源有限的情况下依然能够高效运行。此外,MTP(Multi-Token Prediction)技术通过同时预测多个单词,进一步提升了模型的学习效率。

推理效率的提升
DeepSeek在推理效率方面也取得了重大突破。通过优化蒸馏技术和推理流程,DeepSeek能够在保持高性能的同时,显著降低推理时间。这使得DeepSeek在实际应用中表现出色,尤其在需要快速响应的场景中,如实时翻译和智能客服。
上市公司接入带来的业务提升
多家上市公司宣布接入DeepSeek大模型,预计将带来业务提升和功能优化。华泰证券研究所发布的研报指出,DeepSeek的主要创新包括模型架构、训练方法、蒸馏优化和推理效率提升等,显著提升了AI算法效率和性能。这些创新不仅推动了AI技术的发展,也为企业带来了新的商业机会。
未来展望
DeepSeek的成功不仅在于其技术创新,更在于其对AI产业未来发展的深刻洞察。随着MoE技术和其他创新应用的不断优化,DeepSeek有望在AI领域继续保持领先地位,推动更多企业和行业实现智能化转型。
DeepSeek大模型通过MoE技术等创新应用,不仅在技术上取得了突破,更为AI产业的发展开辟了新的道路。未来,随着更多企业的接入和应用的深入,DeepSeek将继续引领AI新时代。








