随着人工智能技术的飞速发展,AI模型的规模和复杂度不断攀升。DeepSeek作为一家专注于通用人工智能研究的公司,其发布的V3/R1系列模型凭借强劲性能在全球范围内备受瞩目。然而,原版DeepSeek-R1 671B模型体积高达720GB,这对本地部署提出了巨大挑战。如何在保证精度的同时实现模型的轻量化部署,成为业界关注的焦点。

量化技术:模型压缩的核心
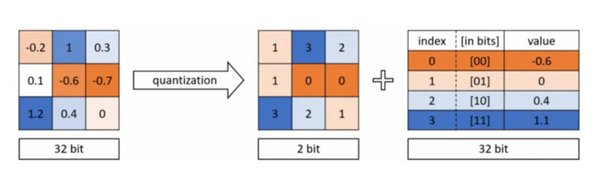
量化技术作为一种高效的模型压缩方法,通过将高精度参数(如32位浮点数)转换为低精度整数(如8位整数),显著减少了模型的内存占用和计算需求。以一个拥有1亿参数的模型为例,采用FP32格式的内存占用约为381.47MB,而使用INT8格式则仅为95.37MB,极大地降低了对硬件资源的要求。
量化技术主要包括两种方法:
-
后训练量化(PTQ):无需原始训练数据,直接将预训练模型转换为定点计算网络,操作简单快捷。
-
量化感知训练(QAT):在训练过程中引入伪量化节点,模拟量化误差,使模型更好地适应低位宽数据环境,从而减少精度损失。
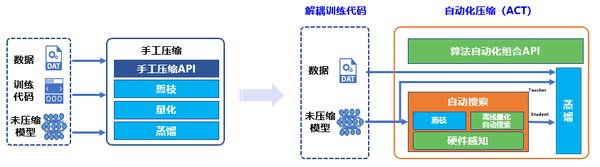
量化感知训练的优势
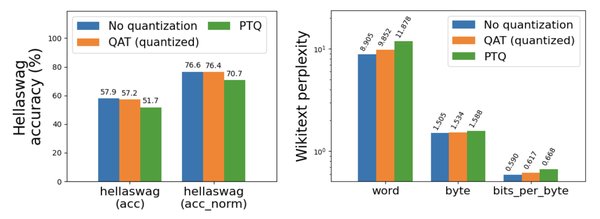
相较于PTQ,量化感知训练(QAT)在复杂任务中表现尤为突出。QAT通过在训练过程中引入量化约束,让模型“学习”如何适应量化误差,从而在量化后保持或接近原始模型的精度。以YOLOX目标检测模型为例,通过QAT技术可以实现模型压缩4倍、推理加速最高2.3倍的效果,同时保持模型精度不低于原始浮点模型。
QAT的核心步骤包括:
-
选择量化策略:确定目标比特数和量化方式。
-
引入伪量化操作:在训练计算图中插入伪量化节点,模拟量化误差。
-
微调训练:使用包含伪量化操作的训练图进行微调训练,优化模型权重。
-
量化与部署:将训练完成的模型量化为低比特模型,并部署到目标设备上。

DeepSeek模型的量化实践
针对DeepSeek系列模型的复杂性,华为的msModelSlim工具提供了多种量化方案,包括W8A8、W8A16等动态量化策略,并正在开发W4A8、W4A16等更高效的算法。具体实施步骤如下:
-
调整离群值抑制:优化量化过程中的异常值处理。
-
选择量化参数:为精度敏感的层保留浮点数计算,确保关键部分的高精度。
-
更新校准集:通过业务校准集提高量化的精确性。
目前,互联网、金融等20多个行业客户已成功在本地部署了DeepSeek-V3/R1的量化模型,显著提升了AI技术的实际应用表现。
量化技术对边缘计算的推动
随着边缘计算的兴起,AI模型的轻量化和高效化成为技术普及的关键。行业数据显示,2023年全球边缘AI芯片市场规模已达76.8亿美元,年复合增长率为28.7%。DeepSeek与网宿科技的技术协同,在算力下沉、动态资源编排、数据隐私合规和成本结构优化等方面实现了显著提升,为智能驾驶、工业质检等场景建立了技术壁垒。
未来展望
量化技术不仅是解决模型部署难题的有效途径,更是推动AI产业健康发展的重要力量。随着深度学习技术的不断进步,量化感知训练将在更多领域得到广泛应用,为模型的高效部署提供更加灵活、经济的解决方案。通过不断创新和优化,量化技术将为AI技术的普及和落地提供强有力的支持。








