近年来,深度语言模型(LLM)在人工智能领域取得了显著进展,而中国在这一领域的表现尤为引人注目。2025年初,深度求索(DeepSeek)公司推出的开源大语言模型DeepSeek R1,不仅在全球引发轰动,更标志着中国在AI技术领域的重大突破。
DeepSeek R1:算法创新与普惠AI的典范
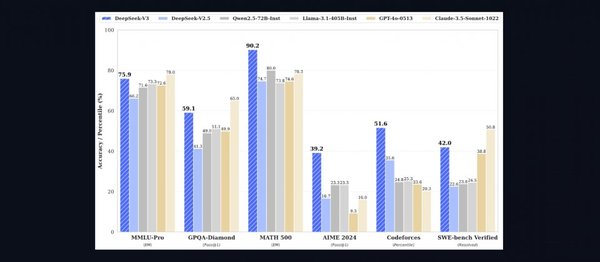
DeepSeek R1的成功在于其算法创新驱动的效率革命。在有限算力条件下,DeepSeek团队成功复现了OpenAI最先进的闭源o1模型的深度推理能力,且API价格仅为后者的1/30。这一成就不仅展示了中国团队的顶尖算法创新能力,也为大模型的训练和推理提供了高效化路径。
此外,DeepSeek R1的开源策略进一步推动了普惠AI的发展。通过公开模型并制定宽松的使用协议,DeepSeek打破了OpenAI试图通过闭源建立的技术壁垒。这种开源精神不仅加速了全球开发者的共同探索,也为中国在AI普惠化进程中占据先机提供了重要支持。


技术细节:DeepSeek的优化与创新
从技术角度看,DeepSeek在预训练数据构建、模型架构和训练超参数等方面进行了深度优化。例如,DeepSeek-V3模型通过提高数学和编程样本比例、扩展多语言覆盖范围,以及采用文档打包方法,显著提升了模型的多样性和完整性。此外,DeepSeek还引入了填充中间(Fill-in-Middle, FIM)策略,使模型能够根据上下文线索准确预测中间文本。
在模型架构方面,DeepSeek-V3采用了Transformer层数、隐藏层维度和注意力头数的创新配置,并结合MoE(Mixture of Experts)层,实现了高效的计算资源利用。这些技术细节不仅展示了DeepSeek团队的研发实力,也为未来大模型的发展提供了重要参考。


未来挑战:追赶与创新并重
尽管DeepSeek R1在模型效果和计算效率上取得了显著优势,但OpenAI随后发布的o3模型在STEM领域的高阶推理能力上实现了进一步提升。这表明,中国在大模型技术方面仍处于追赶状态,需要在人才储备、算力资源和创新生态等方面继续努力。
未来,AI技术的发展将围绕两大命题展开:
-
高效与普惠:通过模型架构、算法和算力的协同创新,实现大模型的普惠化发展。
-
自主创新:在科研队伍、研究投入和实验验证的基础上,探索人工智能的科学化技术方案和计算系统的智能化路径。
结语
DeepSeek R1的成功为中国AI技术的发展点燃了火种,但通向通用人工智能(AGI)的道路依然充满挑战。我们需要在开源生态、工程创新和基础研究等方面持续发力,走出一条人工智能高质量发展之路。正如DeepSeek所展示的,用“小米加步枪”的精神,中国AI依然能够在全球舞台上取得令人瞩目的成就。







