
小样本强化学习算法的背景与意义
近年来,随着人工智能技术的快速发展,强化学习(Reinforcement Learning, RL)在多个领域展现出巨大潜力。然而,传统的强化学习方法通常需要大量的训练数据,这限制了其在资源有限场景中的应用。小样本强化学习(Few-Shot Reinforcement Learning)作为一种新兴技术,旨在通过少量数据实现高效的模型训练,为解决这一问题提供了新的思路。
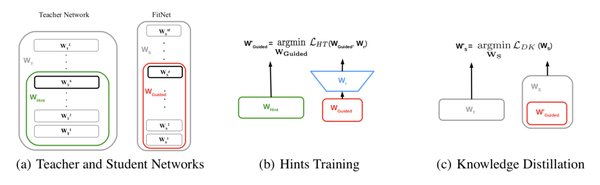
小样本强化学习的核心技术与方法
小样本强化学习的核心在于如何利用有限的样本数据快速学习并泛化到新任务。以下是几种关键技术:
-
知识蒸馏:通过从大型模型中提取知识,将其迁移到小型模型中,从而减少对大量数据的依赖。
-
元学习:通过让模型学习如何学习,使其能够在面对新任务时快速适应。
-
迁移学习:利用已有任务的经验,加速新任务的学习过程。
-
强化学习的改进算法:如REINFORCE++和GRPO,通过优化策略梯度方法,提高训练效率和稳定性。
小样本强化学习的应用场景
小样本强化学习在多个领域展现出广泛的应用前景:
-
自动驾驶:通过模拟环境和少量真实数据,训练自动驾驶模型在复杂交通场景中做出决策。
-
机器人控制:利用小样本强化学习,使机器人能够在未知环境中快速学习并执行任务。
-
医疗诊断:通过少量病例数据,训练模型进行疾病预测和诊断。
-
金融风控:利用历史数据和少量新数据,构建高效的欺诈检测模型。
小样本强化学习的挑战与未来方向
尽管小样本强化学习取得了显著进展,但仍面临一些挑战:
-
数据稀疏性:如何在数据稀疏的情况下保持模型的泛化能力。
-
模型稳定性:如何确保模型在训练过程中的稳定性和一致性。
-
计算资源限制:如何在有限的计算资源下实现高效的模型训练。
-
跨领域泛化:如何使模型在不同领域之间实现有效的知识迁移。
未来,小样本强化学习的研究方向包括:
-
多模态学习:结合视觉、语言等多种模态数据,提升模型的泛化能力。
-
自适应学习:开发能够根据任务需求自动调整学习策略的模型。
-
人机协作:探索人类与AI系统在复杂任务中的协同工作模式。
结语
小样本强化学习作为人工智能领域的前沿技术,正在推动AI从理论走向实际应用。通过不断优化算法和探索新的应用场景,小样本强化学习有望在自动驾驶、机器人控制、医疗诊断等领域发挥更大的作用,为人类社会带来深远影响。





