
GRPO强化学习的背景与意义
近年来,AI语言模型在自然语言处理领域取得了显著进展,但其训练效率和推理能力仍面临挑战。DeepSeek通过引入GRPO(Group Relative Policy Optimization)强化学习算法,成功提升了模型的推理能力和训练效率,成为AI领域的一大突破。

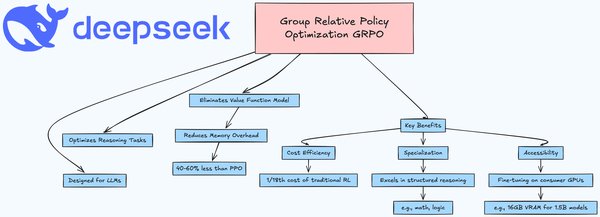
GRPO与传统PPO的对比
GRPO算法在多个方面优于传统的PPO(Proximal Policy Optimization)算法:
-
训练效率:GRPO的训练速度比PPO快30%,内存占用减少50%。(引用自网页4)
-
计算资源:GRPO通过精简架构,减少了所需的大语言模型数量,从4个削减至2个,显著降低了GPU资源需求。(引用自网页2)
-
奖励机制:GRPO采用正则表达式和字符串匹配技术生成奖励信号,避免了复杂的奖励模型训练。(引用自网页2)

GRPO在复杂中文任务中的应用
在复杂中文任务中,GRPO通过以下策略提升模型的推理能力和准确性:
-
分步式提示:引导模型生成结构化推理过程,确保逻辑一致性。(引用自网页2)
-
嵌入背景信息:通过数据验证和合成数据生成,确保模型输出的实用性和安全性。(引用自网页2)
-
分块处理文本:通过“LLM As A Judge”机制剔除错误响应,提升模型自检能力。(引用自网页2)
GRPO的实际效果与未来展望
DeepSeek通过GRPO算法,成功将1B参数的Llama 3.2模型改造成仅需16GB显存的推理模型,展示了GRPO在实际应用中的巨大潜力。(引用自网页2)未来,随着计算资源和数据量的增加,GRPO有望进一步优化,成为AI语言模型训练的主流算法。
结论
GRPO强化学习算法通过提升训练效率和推理能力,为AI语言模型的发展开辟了新的道路。DeepSeek的成功应用展示了GRPO在复杂中文任务中的巨大潜力,未来有望推动AI技术的进一步革新。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...




AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。