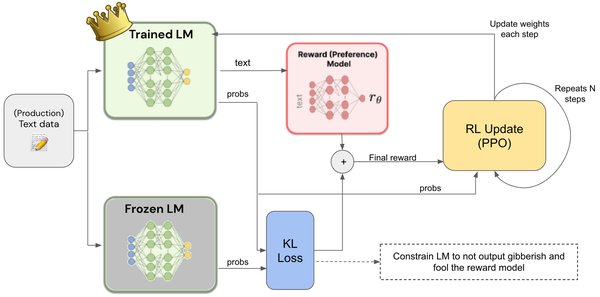

人类反馈的强化学习(RLHF)的技术原理
人类反馈的强化学习(RLHF)是一种结合人类反馈与强化学习的技术,旨在通过人类偏好优化模型行为。其核心在于利用人类反馈作为奖励信号,指导智能体(如语言模型)学习更符合人类期望的策略。RLHF通常包括以下步骤:
-
数据收集:通过人类标注或交互获取反馈数据。
-
奖励模型训练:利用人类反馈训练奖励模型,量化模型输出的质量。
-
策略优化:基于奖励模型,通过强化学习优化模型策略,使其输出更符合人类偏好。
RLHF的独特之处在于,它不仅依赖传统强化学习的试错机制,还通过人类反馈引入更精确的奖励信号,从而提升模型的对齐能力和可控性。

RLHF在生成式人工智能中的应用
RLHF在生成式人工智能中扮演着重要角色,尤其是在语言模型(如ChatGPT)的优化中。以下是其典型应用场景:
-
语言生成:通过人类反馈优化语言模型的生成质量,使其输出更流畅、连贯且符合上下文。
-
指令跟随:在指令驱动的任务中,RLHF帮助模型更好地理解并执行复杂指令。
-
内容安全:通过人类反馈训练模型,避免生成有害或不适当的内容。
在ICML 2023的教程《可信赖生成式人工智能》中,研究科学家详细讲解了RLHF在生成式AI中的应用,强调了其在提升模型可信赖性方面的潜力。
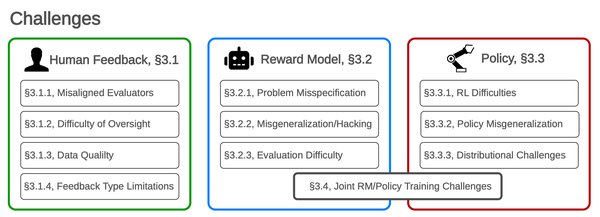
RLHF的优势与挑战
RLHF的优势在于其能够有效对齐模型行为与人类意图,提升模型的可控性和安全性。然而,它也面临以下挑战:
-
数据获取成本高:人类反馈数据的收集和标注需要大量时间和资源。
-
奖励模型偏差:人类反馈可能存在主观偏差,影响奖励模型的准确性。
-
探索与利用的平衡:如何在有限的反馈数据中高效探索并优化策略,是一个关键问题。
RLHF的未来发展方向
随着生成式人工智能的快速发展,RLHF的研究也在不断深化。以下是其未来可能的发展方向:
-
多模态反馈:将人类反馈扩展到图像、视频等多模态数据,提升模型的综合能力。
-
在线学习:开发在线RLHF框架,使模型能够实时学习并适应人类反馈。
-
神经符号结合:结合神经符号方法,提升RLHF的可解释性和推理能力。
总结
人类反馈的强化学习(RLHF)作为一种前沿技术,正在为生成式人工智能的发展提供重要支撑。通过结合人类反馈与强化学习,RLHF不仅提升了模型的对齐能力和可控性,还为构建可信赖的AI系统提供了新的思路。未来,随着技术的不断进步,RLHF有望在更多领域发挥重要作用,推动人工智能向更高层次发展。





