自监督学习的定义与原理
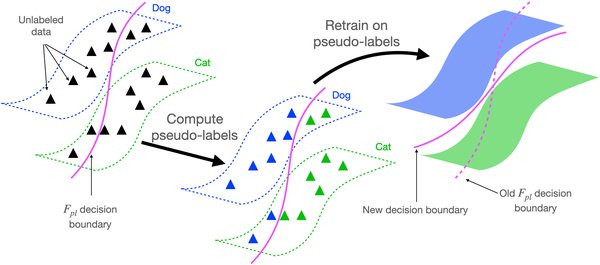
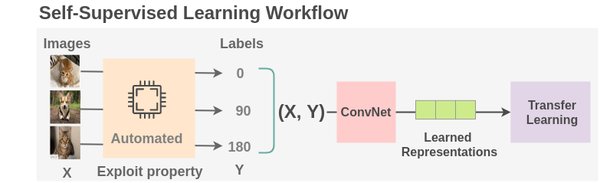
自监督学习(Self-Supervised Learning, SSL)是一种无需人工标注数据的机器学习方法,通过从数据本身生成监督信号来训练模型。与传统的监督学习相比,自监督学习能够利用大量未标注的数据,显著降低对标注数据的依赖,从而提高模型的泛化能力和效率。自监督学习的核心思想是通过设计预训练任务,让模型从数据中学习有用的特征表示,然后将这些特征迁移到下游任务中。
自监督学习在AI大模型中的应用
自监督学习在AI大模型中的应用主要体现在以下几个方面:
-
自然语言处理(NLP):自监督学习在NLP领域的应用尤为广泛,如BERT、GPT等大模型都采用了自监督学习方法进行预训练。这些模型通过预测被掩码的词语或生成连贯的文本,学习到丰富的语言知识,从而在问答、文本生成等任务中表现出色。
-
多模态AI:自监督学习在多模态AI中的应用也日益增多。例如,通过联合学习文本、图像和音频等多模态数据,模型能够更好地理解复杂的信息,并在跨模态任务中取得优异表现。
-
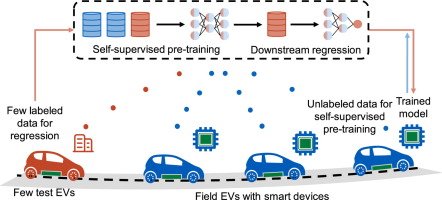
模型优化与压缩:自监督学习还可以用于模型的优化与压缩。通过自监督学习,模型能够在保持高性能的同时,减少参数数量和计算复杂度,从而提高模型的部署效率。

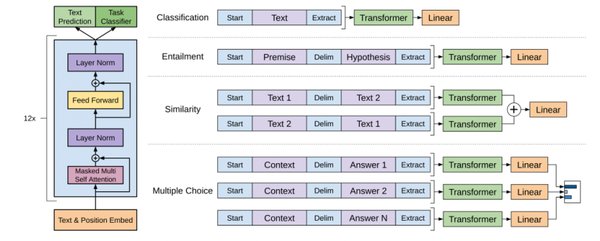
自监督学习的技术挑战与解决方案
尽管自监督学习在AI大模型中取得了显著成果,但仍面临一些技术挑战:
-
数据质量与多样性:自监督学习依赖于大量的未标注数据,但数据的质量和多样性对模型性能有重要影响。如何从海量数据中筛选出高质量、多样化的数据,是自监督学习面临的主要挑战之一。
-
模型泛化能力:自监督学习模型在预训练阶段学习到的特征表示,如何有效地迁移到下游任务中,是一个关键问题。研究人员正在探索多种迁移学习方法,以提高模型的泛化能力。
-
计算资源需求:自监督学习通常需要大量的计算资源进行训练,如何在不牺牲模型性能的前提下,降低计算资源的消耗,是另一个亟待解决的问题。
自监督学习的未来发展趋势
自监督学习作为AI大模型的核心技术,其未来发展趋势主要体现在以下几个方面:
-
跨语言与跨模态学习:随着全球化的加速,跨语言与跨模态学习将成为自监督学习的重要发展方向。未来的自监督学习模型将能够处理多种语言和模态的数据,实现更广泛的应用。
-
个性化与智能化:随着人工智能技术的发展,自监督学习模型将更加个性化和智能化。它们将能够根据用户的个性化需求和行为习惯,提供更加准确和智能的服务。
-
安全性与隐私保护:随着AI技术的广泛应用,安全性与隐私保护成为自监督学习的重要研究方向。未来的自监督学习模型将更加注重数据隐私和模型安全性,确保AI技术的健康发展。
结语
自监督学习作为AI大模型的核心驱动力,正在推动自然语言处理和多模态AI的快速发展。尽管面临一些技术挑战,但随着研究的深入和技术的进步,自监督学习将在未来AI领域发挥更加重要的作用,为各行各业提供更智能、更高效的服务。