
Llama 3.1的发布与版本升级
2024年4月,Meta推出了新一代开源大型语言模型Llama 3,包括Llama 3 8B和Llama 3 70B两个版本,为同类规模的LLM树立了新的基准。然而,在短短三个月内,其他几个LLM的性能已经超过了它们。Meta透露,其最大的Llama 3型号将拥有超过4000亿个参数,目前仍在训练中。LocalLLaMA子论坛泄露了即将推出的Llama 3.1 8B、70B和405B模型的早期基准测试结果,显示Llama 3.1 405B在多个关键人工智能基准测试中超越了目前的领先者OpenAI的GPT-4o。
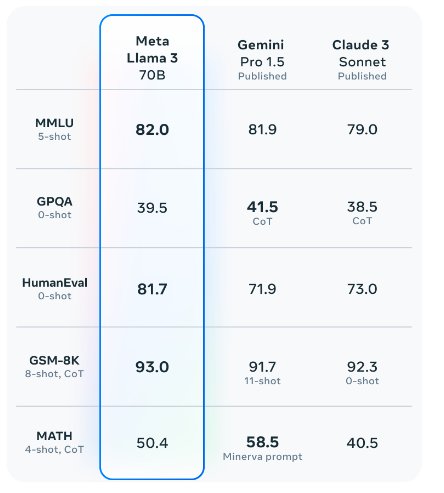

性能提升与训练细节
泄露的数据表明,Llama 3.1 405B在GSM8K、Hellaswag、boolq、MMLU-humanities、MMLU-other、MMLU-stem和winograd等多项测试中均优于GPT-4。然而,它在HumanEval和MMLU-social sciences方面却落后于GPT-4。值得注意的是,这些数据来自Llama 3.1的基本模型,充分释放模型的潜力需要对其进行教学调整。随着Llama 3.1模型指令版本的发布,其中许多结果可能会有所改善。
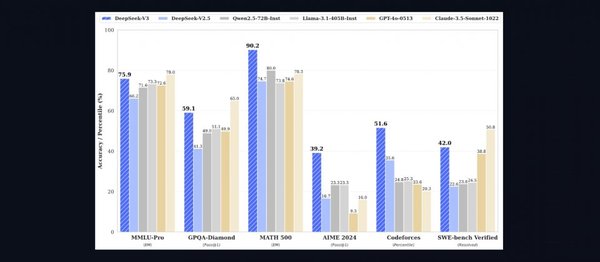
与其他模型的对比
在与其他主流模型的对比中,Llama 3.1展现了强大的竞争力。例如,DeepSeek-V3作为一个拥有671B参数的大规模语言模型,在多个基准测试中表现优于GPT-4o和Claude-3.5 Sonnet。尽管Qwen2.5的参数量较小,但在一些自然语言理解任务上依然表现出色,并且由于其开源特性,受到了社区的高度关注和支持。Llama-3.1具有405B参数,介于DeepSeek-V3和Qwen2.5之间,但其混合专家(MoE)架构使得每个token仅激活约37B参数,从而提高了计算效率并增强了模型的能力。
开源协议与评测结果
Meta在”Llama 3″发布会上表示,他们致力于开放式人工智能生态系统的持续增长和发展,以负责任的方式发布模型。他们坚信,开放会带来更好、更安全的产品、更快的创新和更健康的整体市场。Llama 3.1在多个基准测试中的强劲表现彰显了开源人工智能开发的力量和潜力,这种持续的进步可能会使获取尖端人工智能技术的途径更加民主化,并加速技术行业的创新。
总结与展望
Llama 3.1的发布和性能提升标志着开源大模型在人工智能领域的新里程碑。尽管OpenAI即将推出的GPT-5预计将具备先进的推理能力,可能会挑战Llama 3.1在LLM领域的潜在领导地位,但Llama 3.1在GPT-4o中的强劲表现仍然令人瞩目。未来,随着更多教学调整和指令版本的发布,Llama 3.1有望在更多任务中展现其强大实力,推动开源人工智能生态系统的进一步发展。






