Grok 3的发布与评测争议
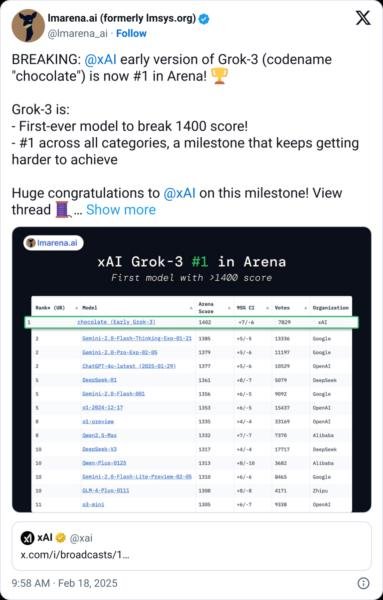
马斯克的人工智能初创公司xAI近日发布了Grok 3大模型,宣称其为“地球上最聪明的人工智能”。Grok 3的计算能力是前代Grok 2的10倍以上,使用了约20万个GPU进行训练,并在多项基准测试中刷新了SOTA(顶尖技术指标)。然而,评测数据却揭示了Grok 3与o3 mini (high)之间的技术博弈。
在AIME 2025数学测试中,Grok 3以87分“击败”了o3 mini (high),但这一结果被质疑为“定制评测”。OpenAI的模型未被允许使用cons@64功能,若开启该功能,o3 mini (high)的得分将接近Grok 3。这种选择性披露数据和模糊对比条件的行为,暴露了AI评测标准的行业潜规则。

速度与逻辑的撕裂
Grok 3在响应速度上确实表现出色,面对复杂的计算题,其速度远超o3 mini (high)。然而,在逻辑能力上,Grok 3却暴露了明显的短板。例如,在面对“老鹰为何能飞?”这样的问题时,Grok 3给出了令人啼笑皆非的回答,而国产模型DeepSeek R1则精准指出了飞行生理结构。
在中文场景中,Grok 3的错误率更是飙升至38%。面对“9.9是否大于9.11”的问题,Grok 3时而将“9.11”理解为日期,时而误判为软件版本号,甚至出现了“9.9美元比9.11人民币值钱”的荒谬结论。这种逻辑缺陷让人质疑Grok 3的真实技术实力。

国产模型的逆袭:技术优化 vs. 算力堆砌
当Grok 3深陷争议时,国产模型DeepSeek R1却以另一种技术逻辑悄然破局。在医疗诊断和金融预测等实战任务中,R1的准确率和错误率均优于Grok 3。R1采用的动态逻辑链分解技术,能将复杂问题拆解为可验证的子步骤,展示了技术优化的重要性。
更关键的是,R1的训练成本不足Grok 3的1%,却能在Chatbot Arena评测中与其得分差距缩小到2%。这种低成本、高精度的技术路径,正在证明技术优化比算力堆砌更有价值。
行业反思:技术神话与信任危机
Grok 3的争议正在重塑整个AI行业。环保组织测算显示,Grok 3单次训练的碳排放相当于1.2万辆汽车的年排放量,引发公众对“AI可持续发展”的拷问。同时,风投机构对“SOTA”的盲目追捧,正将企业逼入“数据造假”的恶性循环。
更深层的矛盾在于评测体系的失控。当企业可以自由选择对比模型、数据集和测试条件时,所谓的“技术突破”越来越像一场皇帝的新衣秀。真正的“最聪明AI”,应该能坦然接受最愚蠢问题的检验,而不是用海量算力制造数据幻觉。
结语
Grok 3与o3 mini (high)的对决,揭示了AI行业的技术博弈与信任危机。在算力堆砌与技术优化之间,行业需要找到更可持续的发展路径。与其追求表面的“技术突破”,不如回归技术本源,让AI的每一次进步都经得起最苛刻的审视。