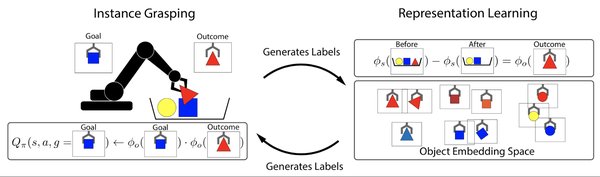
强化学习与自监督学习的融合
近年来,强化学习(Reinforcement Learning, RL)和自监督学习(Self-Supervised Learning, SSL)在人工智能领域取得了显著进展。蚂蚁数科的研究成果展示了无需人工标注数据的情况下,通过自监督学习和强化学习等方法训练模型输出可信结果的能力。这些成果将应用于视频版权保护和智能问答领域,为AI技术的发展提供了新的方向。
自监督学习的优势
自监督学习的核心在于利用未标注的数据进行训练,通过设计预训练任务,模型可以学习到丰富的特征表示。这种方法不仅降低了数据标注的成本,还提高了模型的泛化能力。蚂蚁数科的研究表明,通过自监督学习,模型可以在视频版权保护中准确识别侵权内容,并在智能问答系统中提供高质量的答案。
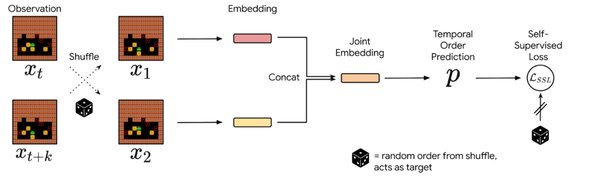
模型透明化:DeepSeek的突破
DeepSeek的研究成果在强化学习领域引起了广泛关注。通过纯强化学习,DeepSeek证明了即使没有过程控制数据,仅通过结果控制也能实现顶级推理模型的性能。这一突破不仅展示了模型透明化的可能性,还为推理模型的民主化提供了可行的路径。
R1 Zero研究的启示
DeepSeek的R1 Zero研究揭示了推理模型无需逐步监督即可自主生成内部过程数据。这一发现挑战了传统观念,表明模型可以通过自我生成的推理链(Chain of Thought, CoT)序列进行训练。这一技术在数学和编程任务中表现尤为突出,为复杂任务的自动化提供了新的思路。

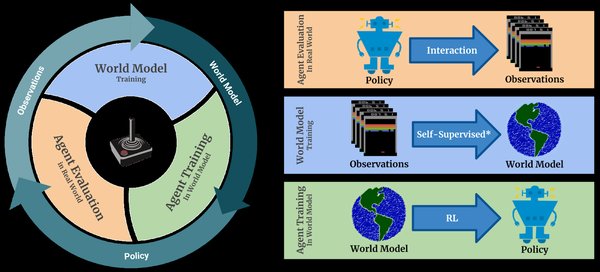
跨域微调:隐私保护的新思路
在模型所有权和数据隐私保护方面,蚂蚁数科提出了创新的跨域微调框架ScaleOT。该框架通过动态层替换和选择性秩压缩,在保持模型性能的同时显著提升了隐私保护效果。ScaleOT不仅降低了90%的算力消耗,还为百亿级参数模型的跨域微调提供了高效和轻量化的解决方案。
ScaleOT的核心创新
ScaleOT框架的核心在于重要性估计和仿真器生成两个阶段。通过强化学习方法确定每层的重要性,并使用轻量级网络作为协调器替换不太重要的层,ScaleOT实现了在模型性能与隐私安全之间的平衡。这一方法在多个模型和数据集上的实验证明了其优越性。
未来展望
随着强化学习和自监督学习的不断发展,AI技术将在更多领域发挥重要作用。DeepSeek的透明化模型和蚂蚁数科的隐私保护技术为AI的广泛应用提供了坚实的基础。未来,这些技术将在视频版权保护、智能问答、自动化编程等领域展现更大的潜力,推动AI技术的普及和应用。
技术融合与社会影响
强化学习与自监督学习的融合不仅提升了模型的性能,还降低了数据标注的成本,使得AI技术更加普惠。DeepSeek的透明化模型为推理模型的发展提供了新思路,而蚂蚁数科的隐私保护技术则为数据安全提供了保障。这些技术的结合将推动AI技术在各行各业的广泛应用,为社会带来深远的影响。
通过不断的技术创新和应用探索,强化学习和自监督学习将在未来AI发展中扮演更加重要的角色,为人类社会带来更多的便利和进步。







