
引言
强化学习(Reinforcement Learning, RL)作为人工智能领域的重要分支,近年来在复杂任务中展现了强大的潜力。无论是游戏AI、自动驾驶,还是自然语言处理,强化学习都取得了显著成果。本文将从基础概念出发,逐步深入探讨强化学习的前沿技术及其应用。
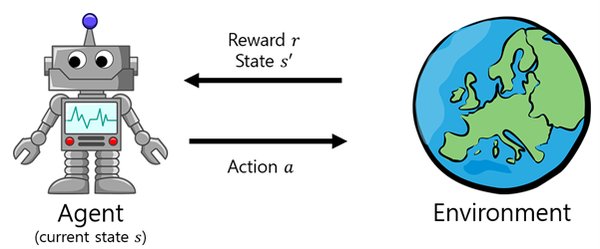
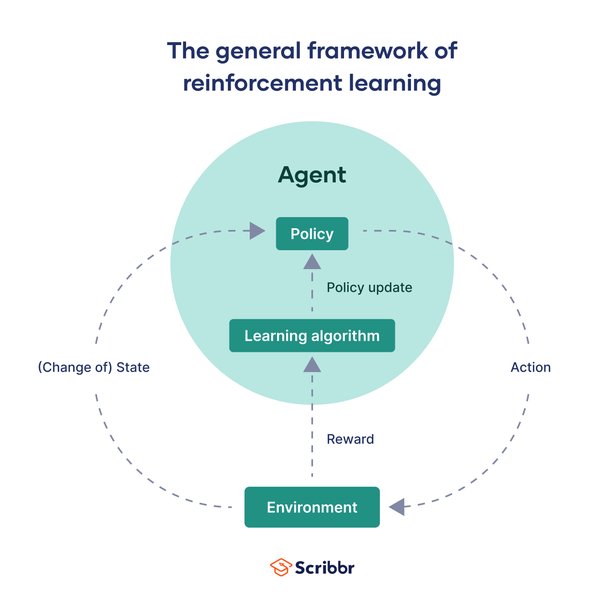
强化学习基础
核心概念
强化学习的核心思想是智能体通过与环境的交互学习决策策略,从而最大化累积奖励。其基本构成包括:
-
智能体(Agent):执行动作的主体。
-
环境(Environment):智能体交互的对象。
-
状态(State):环境的描述。
-
动作(Action):智能体采取的行为。
-
奖励(Reward):智能体根据当前状态和动作获得的反馈。
经典算法
-
Q-learning:通过更新Q值函数来学习最优策略。
-
策略梯度(Policy Gradient):直接优化策略,使智能体的行动符合长期回报。
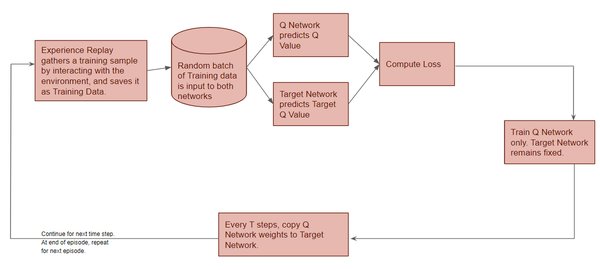
深度强化学习
深度Q网络(DQN)
深度Q网络通过神经网络逼近Q值函数,能够处理大规模和复杂的任务。其关键技术包括:
-
经验回放(Experience Replay):存储历史经验并从中抽取样本,提高训练稳定性。
-
目标网络(Target Network):保持稳定的目标函数,避免Q值剧烈波动。
深度强化学习平台:DeepSeek
DeepSeek是一个高效的强化学习平台,支持多种算法(如DQN、PPO、A3C等)和分布式训练,帮助开发者快速实现智能体训练。
前沿技术探索
基于人类反馈的强化学习(RLHF)
RLHF结合了强化学习与人类主观判断,广泛应用于自然语言处理。其核心步骤包括:
-
预训练语言模型:通过大量语料训练基础模型。
-
训练奖励模型:利用人类偏好数据训练奖励模型。
-
强化学习微调:通过奖励模型优化语言模型。
逻辑推理与强化学习
Logic-RL框架通过基于规则的强化学习,激发大型语言模型的推理能力。其关键技术包括:
-
系统提示(System Prompt):强调模型在回答过程中的细节。
-
严格的格式奖励函数:防止模型走捷径,确保推理过程清晰。
模型蒸馏
模型蒸馏技术将大模型的推理能力迁移到小模型中,显著提升了小模型的性能。例如,DeepSeek-R1-Distill-Qwen-32B通过蒸馏技术,在多个基准测试中表现优异。
强化学习的最佳实践
奖励设计
合理的奖励设计是强化学习成功的关键。设计时应平衡即时奖励与长期奖励,并引入惩罚机制引导智能体学习。
探索与利用的平衡
探索和利用的平衡对于强化学习至关重要。常用策略包括ε-greedy和Boltzmann策略。
多环境并行训练
通过多环境并行训练,可以大幅提高训练效率。DeepSeek支持多环境并行训练,显著加速智能体的学习过程。
总结与未来方向
强化学习在人工智能领域的应用前景广阔。未来,随着RLHF、逻辑推理和模型蒸馏等技术的进一步发展,强化学习将在更多复杂任务中展现其潜力。通过合理设计奖励函数、平衡探索与利用、使用经验回放和目标网络等技术,我们可以显著提升智能体的学习效率,推动人工智能技术的持续进步。
希望本文能为读者提供从理论到实践的完整指南,助力大家在强化学习领域的探索与应用。





