DeepSeek的技术突破:MoE大模型的创新之路
DeepSeek-V3和DeepSeek-R1的发布,标志着中国AI公司在混合专家(MoE)大模型领域取得了重大突破。DeepSeek-V3拥有6710亿参数,每处理一个Token仅激活370亿参数,与GPT-4的参数量相当。其创新之处在于采用了多头潜注意力(MLA)和DeepSeekMoE架构,显著提升了计算效率。
混合专家(MoE)架构的优势
MoE架构通过专家网络和门控网络的结合,实现了对不同任务的精细化处理。DeepSeek-V3通过细粒度专家+通才专家的思路,将知识空间进行离散细化,从而更好地逼近连续的多维知识空间。这种架构不仅提高了计算效率,还降低了训练成本。
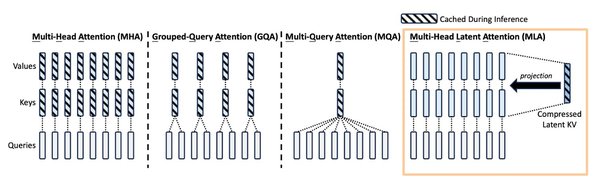
多头潜注意力(MLA)的创新
MLA技术通过低秩键值联合压缩技术,显著减小了KV缓存的大小,同时提高了计算效率。DeepSeek的MLA技术为大模型计算开辟了新的路径,未来可能会有更多精准高效的方法来实现潜空间表征,进一步优化大模型的性能。

创始人梁文锋:从金融到AI的跨界之旅
DeepSeek的创始人梁文锋,1985年出生,毕业于浙江大学电子工程系人工智能方向。他的职业生涯分为两个阶段:先做金融,再做AI。2015年,他创立了杭州幻方科技,专注于通过数学和AI进行量化投资。2023年,他宣布进军通用人工智能(AGI)领域,并成立了大模型公司DeepSeek。
梁文锋的团队基本由本土成员组成,核心成员包括天才工程师罗福莉。他们的努力使得DeepSeek在短短几年内迅速崛起,成为全球AI界的一颗新星。
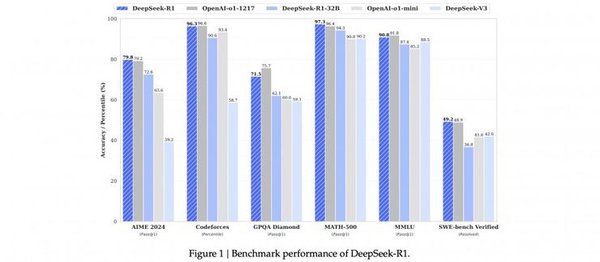
DeepSeek对中国AI产业的影响
DeepSeek的崛起不仅打破了国际巨头在AI领域的垄断,还为中国AI产业带来了新的发展机遇。其开源策略和低成本高性能的特点,使得更多中小企业和个人能够使用高性能的AI模型,推动了AI技术的普及。
开源策略与技术创新
DeepSeek的开源策略和技术创新,使得其在全球AI领域占据了重要地位。其开源项目如FlashMLA、DeepEP、DeepGEMM等,为大模型的研究和应用提供了强大的工具支持。
对中国AI芯片的启示
DeepSeek的成就为国产AI芯片的发展提供了新的启示。通过提升算力使用效率和发展新架构AI芯片,中国芯片产业有望在全球竞争中占据有利地位。
结论
DeepSeek的成功不仅是中国AI技术的一次重大突破,更是全球AI产业格局的一次重要变革。通过混合专家(MoE)架构和创新的训练方法,DeepSeek在性能上与OpenAI相当,同时降低了成本和门槛。未来,DeepSeek有望在更多领域实现技术普惠,推动人机共生与社会包容性发展。
| 模型 | 参数数量 | 激活参数 | 上下文长度 |
|---|---|---|---|
| DeepSeek-V3 | 6710亿 | 370亿 | 128K |
| DeepSeek-R1 | 6710亿 | 370亿 | 128K |
DeepSeek的技术创新和开源策略,为中国AI产业带来了新的发展机遇,未来有望在全球AI领域占据更加重要的地位。




