
引言
2024年5月,中国AI新创公司深度求索(DeepSeek)发布了其最新的大模型DeepSeek-V2,这款模型凭借其创新的混合专家架构(MoE)和高效训练方法,性能直逼OpenAI的顶级模型,引发了全球AI领域的广泛关注。本文将深入探讨DeepSeek-V2的技术突破、创始人梁文锋的创业历程,以及其在全球AI领域的深远影响。
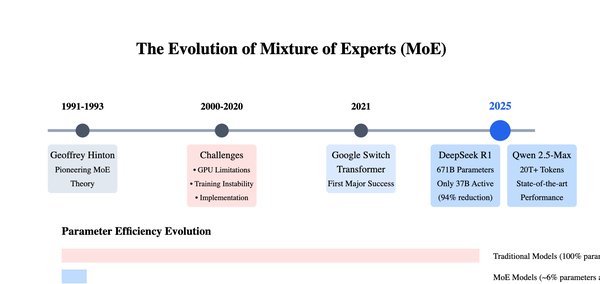
DeepSeek-V2的技术突破
混合专家架构(MoE)
DeepSeek-V2采用了混合专家架构(MoE),这一架构通过将多个专家模型组合在一起,显著提升了模型的推理效率和性能。MoE架构的优势在于,它可以根据任务的不同,动态选择最合适的专家模型进行处理,从而在保持高性能的同时,大幅降低计算成本。
高效训练方法
DeepSeek-V2的训练方法也颇具创新性。通过算法优化和工程优化(如FP8精度训练),DeepSeek-V2的训练成本仅为GPT-4的1/70,推理成本降至1/256。这种高效训练方法不仅降低了模型的使用门槛,还为AI技术的普及和推广提供了有力支持。
多阶段训练流程
DeepSeek-V2的训练流程分为多个阶段,包括冷启动数据微调、强化学习、拒绝采样和再次微调。这一多阶段训练流程确保了模型在不同任务上的表现都能达到最优,进一步提升了模型的实用性和可靠性。


创始人梁文锋的创业历程
从金融到AI
梁文锋的职业生涯分为两个大的阶段,先做金融,再做AI。2015年,他创立了杭州幻方科技,专注于通过数学和AI进行量化投资。2023年5月,他宣布进军通用人工智能(AGI)领域,并成立了深度求索(DeepSeek),致力于前沿AI技术研发。
本土化研发团队
与其他AI模型的研究者不同,梁文锋没有海外经历,毕业于浙江大学电子工程系人工智能方向。整个DeepSeek的研发团队也基本都是本土成员,团队成员来自北京大学、清华大学等顶尖高校,核心成员包括天才工程师罗福莉。
DeepSeek-V2的全球影响
与OpenAI的竞争
DeepSeek-V2的发布,标志着中国AI企业在全球AI领域的崛起。其性能直逼OpenAI的顶级模型,甚至在部分任务上表现更优。DeepSeek-V2的开源策略和低成本API接口,使其在全球范围内迅速获得了大量用户和开发者。
产业重构与社会影响
DeepSeek-V2的低成本高性能特点,使其在金融、医疗、法律等垂直领域快速渗透。它带动了国产大模型生态崛起,部分模型已超越国际竞品。同时,DeepSeek-V2的普及也推动了“算力平权”,降低了AI技术的使用门槛,促进了AI技术的普惠和推广。
结语
DeepSeek-V2的发布,不仅是中国AI技术的一次重大突破,更是全球AI领域的一次重要变革。通过技术创新和高效训练方法,DeepSeek-V2为AI技术的普及和推广提供了有力支持,也为中国AI企业在全球AI领域的崛起奠定了坚实基础。未来,随着AI技术的不断发展,DeepSeek-V2将继续引领全球AI领域的创新与变革。