引言
DeepSeek的横空出世引发了全球性的复现狂潮,仅用30美元的成本便实现了令人瞩目的性能提升,挑战了硅谷巨头在AI领域的霸主地位,预示着大模型平民化时代的到来。其核心在于强化学习的巧妙应用,通过与环境互动学习最佳策略,展现出类似人类的智能行为。DeepSeek的成功降低了AI研究门槛,挑战了算力至上论,加速了AI平民化,但也面临泛化能力、伦理风险和可解释性等挑战。
强化学习的基本原理
什么是强化学习?
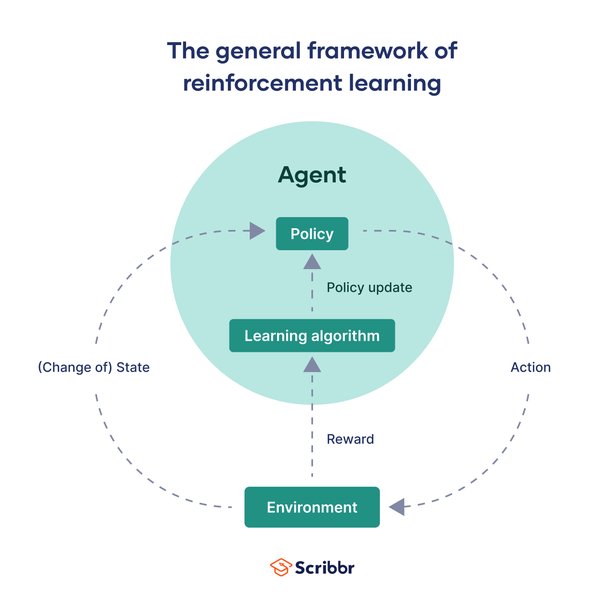
强化学习(Reinforcement Learning, RL)是一种通过奖励和惩罚引导智能体学习的方法,使机器能够在复杂环境中自主决策和进步。其核心思想是智能体通过与环境互动,根据反馈信号(奖励或惩罚)调整策略,以最大化长期累积奖励。
强化学习的核心组件
- 智能体(Agent):学习者或决策者,根据当前状态选择动作。
- 环境(Environment):智能体操作的外部系统。
- 状态(State):在给定时间步的环境快照。
- 动作(Action):智能体在环境中执行的操作。
- 奖励(Reward):智能体执行动作后收到的反馈信号。
强化学习的典型算法
- 时间差分学习(Temporal Difference Learning):解决奖励预测问题的关键算法。
- 策略梯度方法(Policy Gradient Methods):直接优化策略以最大化期望奖励。
- Actor-Critic架构:结合策略优化和价值评估的强化学习框架。

强化学习的应用场景
游戏AI:AlphaGo的突破
AlphaGo是强化学习最引人注目的例子之一,其在2016年和2017年战胜世界顶尖人类围棋选手,展示了强化学习在复杂策略游戏中的强大能力。AlphaGo通过自我对弈不断优化策略,最终超越了人类专业水平。
聊天机器人:ChatGPT的崛起
ChatGPT的训练分为两个阶段,第二阶段采用了基于人类反馈的强化学习(RLHF)技术,以更好地捕捉人类的期望和偏好。RLHF通过人类反馈信号优化模型输出,使其在对话任务中表现出色。
机器人控制:物理技能学习
强化学习在机器人控制领域也取得了显著成功。例如,机器人在模拟环境中学习解决物理问题(如魔方)的运动技能,最终在现实世界中也能成功应用。
其他应用领域
- 网络拥塞控制:优化网络流量管理。
- 芯片设计:自动化芯片布局优化。
- 互联网广告:提升广告投放效果。
- 全球供应链优化:优化物流和库存管理。
强化学习在AI平民化中的作用
DeepSeek的成功案例
DeepSeek通过强化学习实现了低成本高性能的AI模型,挑战了硅谷巨头的霸主地位。其核心在于GRPO(Group Relative Policy Optimisation)算法,通过相对评估优化模型策略,显著降低了训练成本。
降低AI研究门槛
DeepSeek的成功降低了AI研究门槛,使得更多研究者和开发者能够参与AI模型的开发和优化。通过开源和低成本技术,DeepSeek加速了AI平民化进程。
挑战与机遇
尽管强化学习在AI平民化中发挥了重要作用,但仍面临泛化能力、伦理风险和可解释性等挑战。投资者可以关注强化学习相关技术、低成本AI芯片和AI应用场景的投资机会。
结论
强化学习作为AI领域的重要技术,从AlphaGo到DeepSeek,展示了其在复杂任务中的强大能力。DeepSeek的成功标志着AI平民化时代的到来,为更多研究者和开发者提供了参与AI开发的机会。未来,强化学习将继续推动AI技术的发展,同时也需要应对伦理和可解释性等挑战。