生成式模型的技术剖析
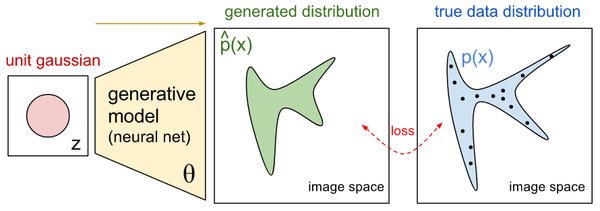
生成式模型是人工智能领域的重要分支,能够通过学习大量数据生成全新、逼真的内容。这类模型的核心在于捕捉数据的内在规律和分布特征,从而生成与真实数据相似的新数据。典型的生成式模型包括生成对抗网络(GAN)和向量量化变分自编码器(VQ-VAE)。
生成对抗网络(GAN)
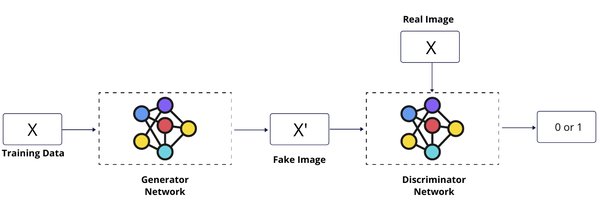
GAN由生成器和判别器两部分组成。生成器负责生成新数据,而判别器则判断数据是否来自真实数据集。在训练过程中,生成器和判别器相互博弈,共同进化,最终使生成器能够生成足以“欺骗”判别器的逼真数据。
向量量化变分自编码器(VQ-VAE)
VQ-VAE采用离散化表示方法,将输入数据编码为一组离散向量,并通过解码器还原为原始数据。这种方法不仅有助于数据压缩,还能提高生成数据的多样性和可控性。
大语言模型的技术特点
大语言模型是生成式模型的重要应用之一,具备强大的文本生成和理解能力。这类模型通常具有数十亿甚至上百亿的参数规模,能够学习到丰富的语言知识和推理能力。
GPT系列模型
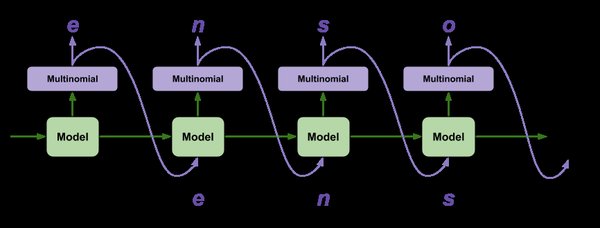
GPT系列模型以自回归方式生成文本,即根据之前的文本内容预测下一个词的概率分布。这种逐词生成的方式使GPT模型能够生成连贯、自然的文本段落。GPT-3作为该系列的最新成员,凭借其1750亿的庞大参数规模,在多项自然语言处理任务中取得了卓越性能。
BERT系列模型
BERT系列模型采用基于双向Transformer的编码器结构,能够同时考虑文本上下文的信息。这种双向编码方式使BERT模型在文本理解任务中表现出色,如情感分析、问答系统等。
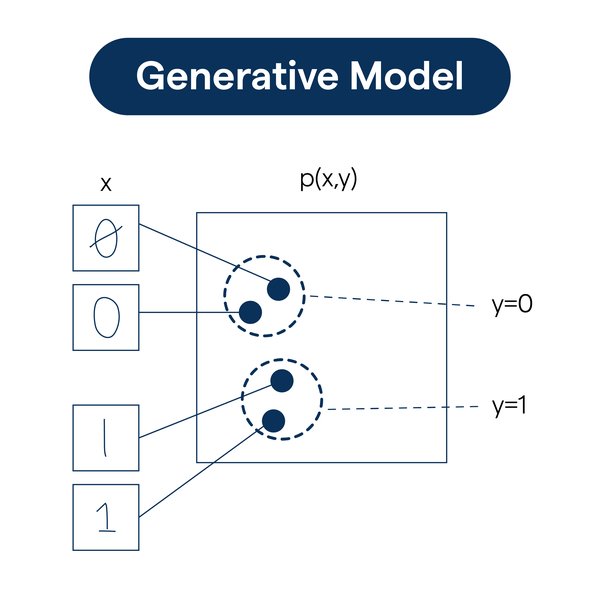
生成式模型的应用场景
生成式模型在多个领域展现出强大的应用潜力,以下是几个典型场景:
| 应用领域 | 具体应用 |
|---|---|
| 自然语言生成 | 生成文章、故事、对话等 |
| 图像生成与编辑 | 定制化图像生成、风格转换等 |
| 智能语音合成 | 自然、流畅的语音输出,支持多语言和风格 |
模型微调与调优
生成式模型的性能提升离不开模型微调和调优技术。以下是两种常见的微调方法:
全量微调
全量微调需要调整模型的所有参数,虽然效果显著,但可能浪费资源。例如,对于千亿参数的大模型,全量微调可能无法显著提升信息传达效率。
LoRA微调
LoRA微调通过叠加一组可训练的低秩矩阵,在不直接修改原有模型参数的情况下完成微调。这种方法显著降低了资源消耗,同时保持了模型的性能。
未来发展趋势
生成式模型技术正在不断进步,未来将在更多领域发挥重要作用。例如:
- 医疗领域:开发能够理解医学专业术语并生成高质量医疗报告的智能系统。
- 教育领域:为学生提供个性化的辅导和学习资源。
- 娱乐领域:创造更加沉浸式的虚拟现实体验。
生成式模型作为人工智能领域的重要技术之一,其强大的生成和理解能力正在为各行各业带来巨大的变革和创新机遇。我们有理由相信,在不久的将来,这些技术将成为推动社会进步和发展的重要力量。







