
DeepSeek的崛起与MoE架构
最近,AI领域的新星DeepSeek凭借其创新性的混合专家架构(MoE)和低训练成本迅速崛起,甚至在应用商店下载榜上超越了ChatGPT。DeepSeek由幻方量化创立,专注于大语言模型(LLM)和相关技术的开发,具备强大的自然语言处理能力。其技术亮点包括创新性算法、混合专家架构(MoE)和低训练成本。DeepSeek在性能上与ChatGPT各有优势,但在成本和开源策略上更具竞争力。
什么是MoE架构?
混合专家模型(Mixture of Experts,MoE)是一种先进的神经网络架构,旨在通过整合多个模型或“专家”的预测来提升整体模型性能。MoE模型的核心思想是将输入数据分配给不同的专家子模型,然后将所有子模型的输出进行合并,以生成最终结果。这种分配可以根据输入数据的特征进行动态调整,确保每个专家处理其最擅长的数据类型或任务方面,从而实现更高效、准确的预测。
MoE模型的主要组成部分包括:
- 专家(Experts):模型中的每个专家都是一个独立的神经网络,专门处理输入数据的特定子集或特定任务。
- 门控网络(Gating Network)/路由器(Router):门控网络的作用是决定每个输入样本应该由哪个专家或哪些专家来处理。
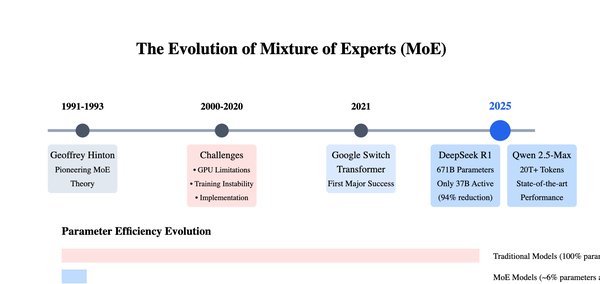
DeepSeek的MoE架构创新
DeepSeek创新性地应用MoE架构提高训练效率。MoE并非DeepSeek首创,其最早在20世纪90年代就已经被提出,随后在机器学习领域的专家Jordan和Jacobs的完善下,在1994年进一步发展成“分层混合专家”模型的概念。DeepSeek在没有庞大算力支持的情况下,转而对模型进行深度优化,放弃了DeepSeek-V1的Dense路线,转向在同等算力下有着更高效率的MoE,并且针对MoE的各种问题开发了一系列的解决措施。比如设计了一种创新的无辅助损失负载均衡策略,通过预先设置的负载均衡逻辑来动态调整负载,抛弃传统的额外的损失函数方案。
DeepSeek的技术亮点
DeepSeek在MoE架构的基础上,进一步引入了多头潜在注意力机制(MLA)和多令牌预测(MTP)机制,显著提高了模型的训练和推理效率。
多头潜在注意力机制(MLA)
MLA通过将注意力头的键和值进行线性变换,将他们压缩到一个共享的低维潜在向量空间,接下来推理时只需要拿着压缩后的缩略图倒腾即可,在得到结论后再把对应的压缩包解压,计算其中的键和值并输出最终答案。
多令牌预测(MTP)
MTP机制下生成出来的文字内容会更加流畅和自然,因为MTP机制就等于将“走一步看一步”的写作方式,变成了“先拟大纲再填充字词”。DeepSeek先想好要写什么,然后再通过MTP生成一系列字词,选择其中相关性更强的部分组合,这也是为什么大家在看DeepSeek生成的文字内容时,会感觉更有“人”味,因为这就是人类的写作方法。
DeepSeek的开源策略
DeepSeek采取开源架构,在前不久的“开源周”上,它大方地开放了多个技术/工具/架构,每一个都将对AI大模型产业产生深远影响。
FlashMLA
FlashMLA,官方的解释是一款面向Hopper GPU的高效MLA解码内核,并针对可变长度序列的服务场景进行了优化。用更通俗的说法来解释,就是一个针对H系列计算卡的超频“外挂”,因为FlashMLA的效果实在是太炸裂了。
DeepEP
DeepEP是一款针对MoE模型训练和推理所设计的EP(专家并行)通信库,旨在解决这类模型在常规通信机制下的高延迟、低数据传输速率等问题。
DeepGEMM
DeepGEMM是一个专为简洁高效的 FP8 通用矩阵乘法(GEMM)设计的库,具有细粒度缩放功能,支持普通和混合专家(MoE)分组的 GEMM。
结语
DeepSeek的MoE架构和创新性技术为AI领域带来了革命性的突破。其开源策略不仅推动了整个AI行业的发展,也为未来的大模型训练和推理提供了新的思路和方向。随着DeepSeek的不断进步和优化,我们有理由相信,AI技术将在更多领域得到广泛应用,为人类社会带来更多的便利和进步。







