
引言
大型语言模型(LLM)作为人工智能领域的核心技术,近年来经历了飞速的发展。从2017年Transformer架构的提出,到2025年DeepSeek-R1的推出,LLM在自然语言处理、多模态整合和复杂推理任务中取得了显著的突破。本文将回顾LLM的进化历程,探讨其关键技术突破,并分析开源和成本高效模型对AI行业的影响。
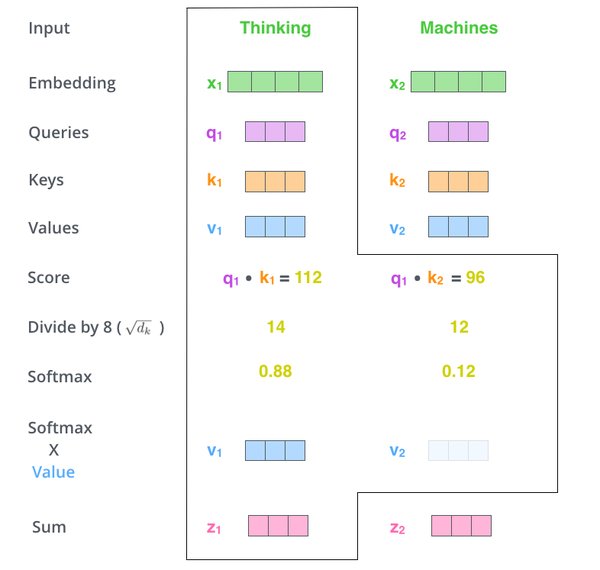
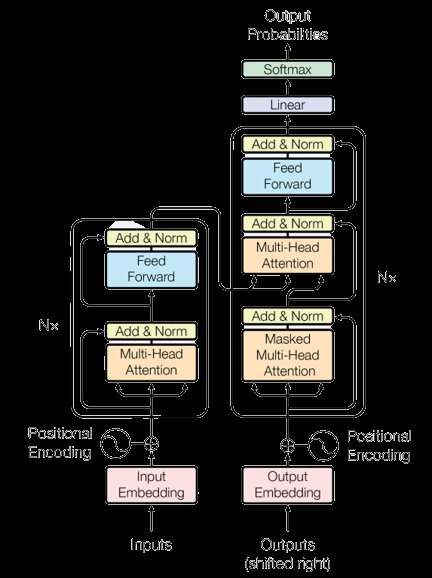
Transformer革命:LLM的基石
2017年,Vaswani等人提出的Transformer架构彻底改变了自然语言处理(NLP)领域。Transformer通过自注意力机制(Self-Attention)解决了早期模型如循环神经网络(RNN)和长短期记忆网络(LSTM)在长程依赖性和顺序处理方面的局限性。自注意力机制允许模型动态关注输入的相关部分,从而提高了全局上下文理解能力。
关键创新
- 自注意力机制:权衡每个标记相对于其他标记的重要性,实现并行计算。
- 多头注意力:多个注意力头并行操作,专注于输入的不同方面。
- 前馈网络和层归一化:稳定训练并支持更深的架构。
- 位置编码:保留词序信息,不牺牲并行化。
Transformer的引入为构建大规模高效语言模型奠定了基础,推动了LLM的快速发展。
预训练模型时代:BERT与GPT的崛起
2018年至2020年,预训练Transformer模型的兴起标志着NLP的新时代。BERT和GPT系列模型展示了大规模预训练和微调范式的强大功能。
BERT:双向上下文理解
2018年,谷歌推出的BERT采用双向训练方法,能够同时从两个方向捕获上下文。BERT通过掩码语言建模(MLM)和下一句预测(NSP)任务,在文本分类、命名实体识别和情感分析等任务中表现出色。
GPT:生成式预训练
OpenAI的GPT系列模型专注于自回归文本生成。GPT-3凭借1750亿参数展示了卓越的少样本和零样本学习能力,推动了内容创作、对话代理和自动推理等应用的发展。
后训练对齐:减少幻觉与提升人类一致性
随着LLM生成能力的提升,如何确保模型生成内容与人类价值观一致成为关键挑战。2021年至2022年,研究人员通过监督微调(SFT)和基于人类反馈的强化学习(RLHF)技术,改善了模型与人类意图的一致性。
ChatGPT:对话式AI的突破
2022年,OpenAI推出的ChatGPT通过对话聚焦的微调和RLHF技术,实现了自然的多轮对话,标志着对话式AI的重大进展。
多模态模型:连接文本、图像与音频
2023年至2024年,多模态大型语言模型(MLLMs)如GPT-4V和GPT-4o整合了文本、图像、音频和视频处理能力,实现了更丰富的交互和复杂问题解决。
GPT-4V:视觉与语言的结合
GPT-4V能够解释图像、生成标题并回答视觉问题,在医疗保健和教育等领域具有广泛应用。
GPT-4o:全模态前沿
GPT-4o通过整合音频和视频输入,进一步扩展了多模态能力,成为娱乐和设计等行业的多功能工具。
开源与成本高效模型:AI普及化的推动力
2023年至2024年,开源和开放权重AI模型获得了广泛关注,推动了先进AI技术的普及。
DeepSeek-R1:成本高效的推理模型
2025年,DeepSeek推出的R1模型通过专家混合架构(MoE)和优化算法,显著降低了运营成本,成为成本高效LLM的代表。
开源模型的影响
开源模型如Meta AI的LLaMA系列和Mistral AI的Mistral 7B,促进了社区驱动的创新,推动了AI技术的民主化。
结论
从Transformer架构的引入到DeepSeek-R1的推出,LLM的演变标志着人工智能领域的革命性进展。通过自注意力机制、生成能力、多模态整合和推理模型的创新,LLM在广泛的应用中实现了接近人类的表现。开源和成本高效模型的兴起,进一步推动了AI技术的普及,为各行各业的创新开辟了新的可能性。
随着LLM的不断发展,未来AI将更加注重推理能力、多模态整合和与人类价值观的一致性,推动人工智能朝着更加包容和影响力深远的方向迈进。






