引言
在AI技术飞速发展的今天,DeepSeek-V2凭借其创新的技术架构和高效的推理性能,成为了AI领域的一颗新星。本文将深入探讨DeepSeek-V2的技术创新及其对AI行业的影响,揭示其在降低算力消耗、提高推理效率方面的独特优势。
技术创新:MoE架构与MLA机制
MoE架构:高效训练的基石
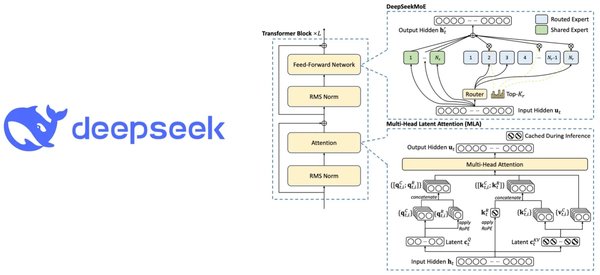
DeepSeek-V2采用了多专家模型(MoE)架构,这一架构通过将巨大的AI模型切割成多个子模型,实现了高效的选择性激活。具体来说,MoE架构通过门控网络决定每个输入样本应由哪些专家处理,从而显著降低了计算量。
“`markdown
| 模型 | 参数量 | 激活参数 | 计算性能 |
|---|---|---|---|
| DeepSeek-V2 | 671B | 32B | 高 |
| ChatGPT-4 | 175B | 175B | 中 |
“`
MLA机制:推理效率的提升
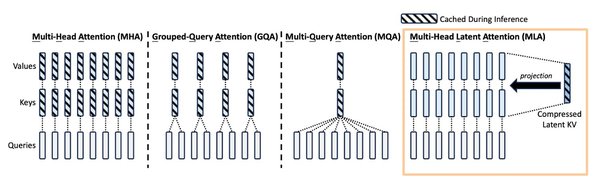
多头潜在注意力机制(MLA)是DeepSeek-V2的另一大创新。MLA通过将注意力头的键和值压缩到共享的低维潜在向量空间,大幅减少了KV缓存,从而提高了GPU的使用效率。以DeepSeek-V2为例,MLA能将KV缓存减少93.3%,显著提升了推理效率。
效率优化:MTP机制与强化学习
MTP机制:预测能力的增强
DeepSeek-V2引入了多令牌预测(MTP)机制,通过并行处理多个令牌,显著提高了模型的训练和推理效率。MTP机制不仅加快了推理速度,还使得生成的文本更加流畅自然。
强化学习:自主学习的未来
DeepSeek-V2通过强化学习技术,实现了AI模型的自主学习。这种技术让AI在不断的自问自答中进化,逐步提升其智能水平。DeepSeek-R1-Zero模型在强化学习过程中甚至出现了“顿悟”现象,展现了AI自主学习的巨大潜力。
行业影响:开源与算力优化
开源精神:推动AI行业进步
DeepSeek-V2的开源策略不仅降低了AI模型的推理成本,还推动了整个AI行业的技术进步。通过开源MoE架构、MLA机制等核心技术,DeepSeek为AI企业提供了高效的工具,促进了行业的交流与学习。
算力优化:降低运营成本
DeepSeek-V2通过一系列优化措施,显著降低了算力消耗和运营成本。例如,DeepSeek的优化技术使得H800计算卡的算力超越了H100的默认算力,同时将内存带宽提升了50%。这些优化不仅降低了AI模型的运营成本,还提高了其市场竞争力。
“`markdown
| 优化技术 | 算力提升 | 内存带宽提升 | 成本降低 |
|---|---|---|---|
| FlashMLA | 580TFLOPS | 3000GB/s | 40% |
| DeepEP | 92% | 微秒级 | 30% |
| DeepGEMM | FP8精度 | 细粒度缩放 | 20% |
“`
结论
DeepSeek-V2凭借其创新的MoE架构、MLA机制和MTP机制,在AI模型的训练和推理效率上实现了革命性突破。其开源策略和算力优化措施不仅降低了AI模型的运营成本,还推动了整个AI行业的技术进步。未来,随着AI技术的不断发展,DeepSeek-V2有望在更多领域发挥其独特优势,为AI行业带来更多的创新与突破。






