
引言
在人工智能领域,大型语言模型的训练成本一直是业界关注的焦点。2024年12月,深度求索公司发布的DeepSeek-V3模型,以其混合专家(MoE)架构和FP8混合精度训练技术,成功实现了低成本与高效能的完美结合,成为AI大模型领域的新标杆。
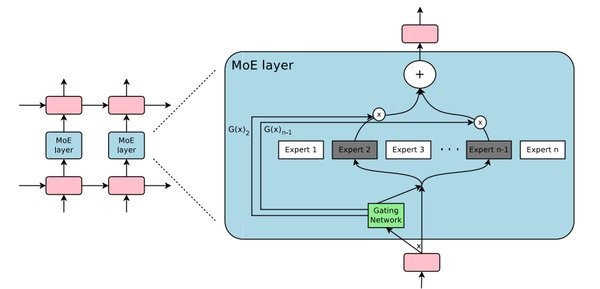
架构创新:混合专家(MoE)架构
DeepSeek-V3采用了混合专家架构,这一架构通过将任务分配给多个“专家”网络来处理,每个专家网络擅长处理特定类型的任务。这种设计不仅提高了模型的灵活性,还显著降低了计算资源的消耗。
关键组件
- 专家网络:每个专家网络都是一个前馈网络,专门处理特定类型的子任务。
- 门控网络:负责根据输入数据决定各个专家网络的权重,确保最合适的专家被激活。
- 选择器:根据门控网络的权重,选择最合适的专家或专家组合来处理任务。
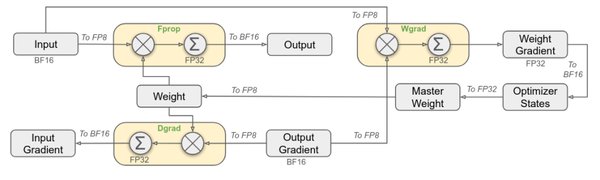
训练技术:FP8混合精度训练
为了进一步提升训练效率,DeepSeek-V3采用了FP8混合精度训练技术。这一技术通过降低数据精度来减少GPU内存的使用,从而加速训练过程并降低能耗。
技术优势
- 计算速度提升:FP8仅占FP32的1/4空间,显著提升了计算速度。
- 存储消耗降低:低精度存储减少了显存占用,使得更大规模的模型训练成为可能。
- 训练稳定性:通过细粒度量化和在线量化等技术,确保了训练的稳定性和精度。
性能表现:超越现有模型
DeepSeek-V3在多项测试中展现了卓越的性能,不仅超越了Qwen2.5-72B和Llama-3.1-405B等知名开源模型,更在数学能力测试中超越了所有现有开源和闭源模型。
测试结果对比
| 模型 | 数学能力测试得分 | 生成速度(token/秒) |
|---|---|---|
| DeepSeek-V3 | 95 | 60 |
| GPT-4 | 90 | 50 |
| Claude-3.5-Sonnet | 88 | 55 |
低成本优势:训练成本仅为1%
DeepSeek-V3的训练成本仅为557.6万美元,这一数字仅为同类模型的1%。这一显著的成本优势,得益于其高效的训练技术和优化的硬件利用。
成本对比
| 模型 | 训练成本(百万美元) |
|---|---|
| DeepSeek-V3 | 5.576 |
| GPT-4 | 500 |
| Claude-3.5-Sonnet | 450 |
结论
DeepSeek-V3的成功不仅在于其高性能,更在于其通过创新架构和训练技术实现的低成本。这一模型的出现,为AI大模型的发展提供了新的思路和方向,预示着AI技术将更加普及和高效。
通过深入分析DeepSeek-V3的架构、训练技术和性能表现,我们可以看到,这一模型不仅在技术上实现了突破,更在成本控制上树立了新的标准。未来,随着更多类似技术的应用,AI大模型的发展将更加迅速和广泛。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...











AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。