
DeepSeek-R1模型的崛起
在2025年世界经济论坛上,中国深度求索公司发布了其最新开源模型DeepSeek-R1,这一模型在技术上实现了重要突破,尤其是在数学、代码、自然语言推理等任务上,其性能比肩美国开放人工智能研究中心(OpenAI)的o1模型正式版。DeepSeek-R1模型的训练成本仅为560万美元,远远低于美国科技巨头在人工智能技术上投入的数亿美元乃至数十亿美元。
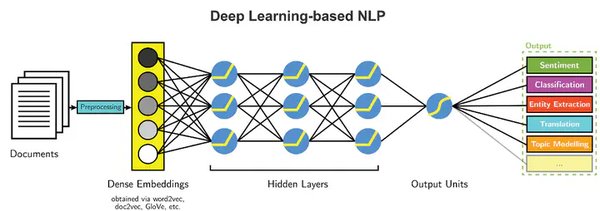
核心技术解析
DeepSeek-R1模型的核心技术包括:
- 自然语言处理:通过深度学习技术,模型能够理解和生成自然语言,实现高效的文本分析和生成。
- 深度学习:利用大规模强化学习(RL)创建推理模型,提高模型在复杂任务上的表现。
- 大数据处理:通过处理和分析大规模数据,模型能够不断优化和提升其性能。

低成本高性能的优势
DeepSeek-R1模型的低成本高性能使其在全球AI竞赛中占据显著优势。以下是其成本与性能的对比表格:
| 模型 | 训练成本 | 性能表现 |
|---|---|---|
| DeepSeek-R1 | 560万美元 | 比肩o1 |
| OpenAI o1 | 数亿美元 | 高 |
| 谷歌模型 | 数十亿美元 | 高 |
未来展望
DeepSeek-R1模型的成功发布,不仅展示了中国在AI领域的强大实力,也为全球AI技术的发展提供了新的思路和方向。随着技术的不断进步和成本的进一步降低,DeepSeek-R1模型有望在更多领域得到广泛应用,推动AI技术的普及和发展。
通过本文的介绍,我们可以看到DeepSeek-R1模型在低成本高性能方面的显著优势,以及其在全球AI竞赛中的潜在影响力。未来,随着更多类似技术的出现,AI领域将迎来更加广阔的发展空间。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...








AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。