市面上所谓“本地部署”方案,多为参数量缩水90%的蒸馏版,背后原因是671B参数的MoE架构对显存要求极高——即便用8卡A100也难以负荷。因此,想在本地小规模硬件上跑真正的DeepSeek-R1,被认为基本不可能。
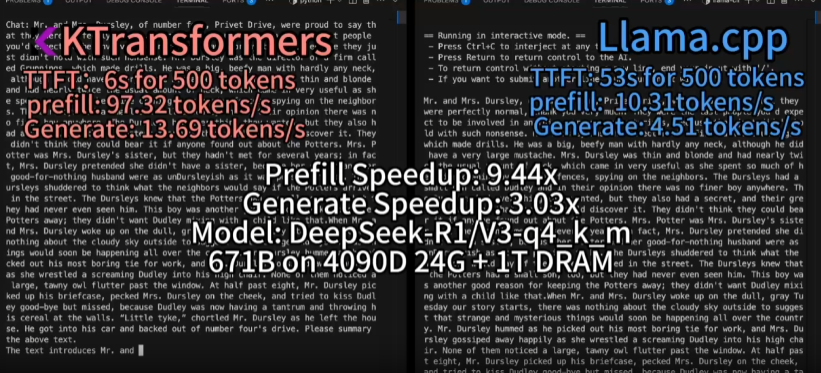
但是清华大学的KTransformers开源项目可以支持24G显存在本地运行DeepSeek-R1、V3的671B满血版。预处理速度最高达到286 tokens/s,推理生成速度最高能达到14 tokens/s。KTransformers还提供了兼容Hugginface Transformers的API与ChatGPT式Web界面,极大降低了上手难度。
4090单卡部署满血版DeepSeek-R1步骤:
一:准备环境
1、安装CUDA 12.1及更高版本:下载地址
安装后添加环境变量:
# Adding CUDA to PATH export PATH=/usr/local/cuda/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH export CUDA_PATH=/usr/local/cuda
2、安装Linux-X86_64与GCC,G ++和CMAKE
sudo apt-get update sudo apt-get install gcc g++ cmake ninja-build
3、使用conda创建一个虚拟环境,并使用python = 3.11版本来运行
conda create --name ktransformers python=3.11 conda activate ktransformers
4、确保安装了PyTorch, packaging, ninja
pip install torch packaging ninja cpufeature numpy二、开始部署
三种方式选其一
1、使用docker:docker使用教程
2、使用pip安装(linux系统):
pip install ktransformers --no-build-isolation3、下载源代码编译安装
下载源代码:
git clone https://github.com/kvcache-ai/ktransformers.git
cd ktransformers
git submodule init
git submodule update
编译(linux):
bash install.sh编译(windows)
install.bat三、测试代码
1、运行测试代码(更改DeepSeek-v2-lite-chat-gguf为你想用的模型,会自动从hugging face上下载,确保你的电脑能打开这个网站):
# Begin from root of your cloned repo!
# Begin from root of your cloned repo!!
# Begin from root of your cloned repo!!!# Download mzwing/DeepSeek-V2-Lite-Chat-GGUF from huggingface
mkdir DeepSeek-V2-Lite-Chat-GGUF
cd DeepSeek-V2-Lite-Chat-GGUFwget https://huggingface.co/mzwing/DeepSeek-V2-Lite-Chat-GGUF/resolve/main/DeepSeek-V2-Lite-Chat.Q4_K_M.gguf -O DeepSeek-V2-Lite-Chat.Q4_K_M.gguf
cd .. # Move to repo’s root dir
# Start local chat
python -m ktransformers.local_chat –model_path deepseek-ai/DeepSeek-V2-Lite-Chat –gguf_path ./DeepSeek-V2-Lite-Chat-GGUF# If you see “OSError: We couldn’t connect to ‘https://huggingface.co’ to load this file”, try:
# GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/deepseek-ai/DeepSeek-V2-Lite
# python ktransformers.local_chat –model_path ./DeepSeek-V2-Lite –gguf_path ./DeepSeek-V2-Lite-Chat-GGUF
2、参数解释:
--model_path (必需):模型的名称(例如“ deepseek-ai/deepseek-v2-lite-chat”,它将自动从hugging face上下载配置)。或者,如果您已经有本地文件,则可以直接使用该路径来初始化模型。
PS:目录中不需要.safetensors文件。我们只需要配置文件来构建模型和令牌。
--gguf_path (必需):包含GGGUF文件的目录的路径,可以从hugging face下载。请注意,目录应仅包含当前模型的GGGUF,这意味着您需要每个模型一个单独的目录。
--optimize_rule_path (qwen2moe和deepSeek-v2除外),必需的:包含优化规则的yaml文件的路径 KtransFormers中有两个规则文件deepSeek-v2和qwen2-57b-a14,两个SOTA MOE模型。
--max_new_tokens :int(默认= 1000)。最大生成新的token数量。
--cpu_infer :int(默认值= 10)。用于推理的CPU数量。理想情况下应设置为(核心总数-2)。
3、推荐使用的模型
| Model Name 模型名称 | 型号大小 | VRAM | 最小DRAM | 推荐的DRAM |
|---|---|---|---|---|
| DeepSeek-R1-q4_k_m | 377G | 14G | 382G | 512G |
| DeepSeek-V3-q4_k_m | 377G | 14G | 382G | 512G |
| DeepSeek-V2-q4_k_m DeepSeek-V2-E_K_M | 133G | 11G | 136G | 192G |
| DeepSeek-V2.5-q4_k_m DeepSeek-V2.5-C4_K_M | 133G | 11G | 136G | 192G |
| DeepSeek-V2.5-IQ4_XS | 117G | 10G | 107G | 128G |
| Qwen2-57B-A14B-Instruct-q4_k_m | 33G | 8G | 34G | 64G |
| DeepSeek-V2-Lite-q4_k_m | 9.7G | 3G | 13G | 16G |
| Mixtral-8x7B-q4_k_m mixral-8x7b-e_k_m | 25G | 1.6G | 51G | 64G |
| Mixtral-8x22B-q4_k_m | 80G | 4G | 86.1G | 96G |
| InternLM2.5-7B-Chat-1M Internet2.5-7b-cat-1m | 15.5G | 15.5G | 8G(32K上下文) | 150G(1M上下文) |
4、直接使用transformers启动服务器,Model_Path应该包括SAFETENSORS
ktransformers –type transformers –model_path /mnt/data/model/Qwen2-0.5B-Instruct –port 10002 –web True
5、访问:http://localhost:10002/web/index.html#/chat
四、个人测试的配置:
1、硬盘2T
2、cpu>=65核
3、内存>=512G






