
BERT的崛起与自然语言处理的变革
自2018年BERT(Bidirectional Encoder Representations from Transformers)模型问世以来,自然语言处理(NLP)领域迎来了革命性的进展。BERT通过双向Transformer架构和掩码语言模型(Masked Language Model, MLM)预训练,在多项NLP任务中取得了突破性成绩。其成功不仅在于模型架构的创新,更在于其对上下文信息的深度捕捉能力。
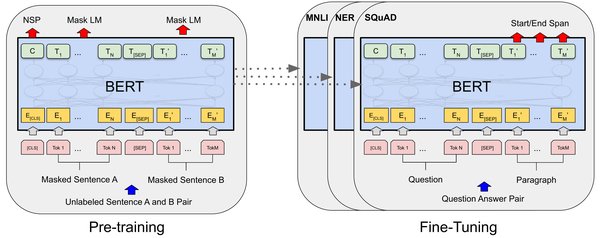
BERT相关模型的演进
在BERT的基础上,研究者们提出了多种改进模型,进一步推动了NLP技术的发展。以下是几款重要的预训练模型及其特点:
-
XLNet:通过引入排列语言模型(Permutation Language Model),克服了BERT在预训练和微调阶段不一致的问题。
-
RoBERTa:通过优化训练策略(如更长的训练时间、更大的批次规模),显著提升了BERT的性能。
-
SpanBERT:专注于处理跨度的表示,特别适用于需要理解文本片段的任务,如问答系统。
-
MT-DNN:结合多任务学习,增强了模型在不同任务间的泛化能力。
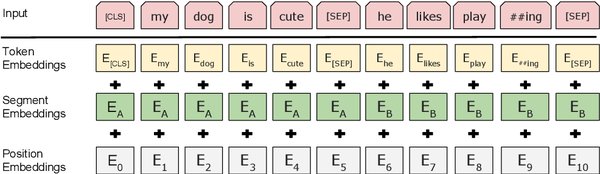
BERT表现出色的原因分析
BERT的成功可以归结于以下几点:
-
双向上下文建模:与传统的单向模型相比,BERT能够同时捕捉上下文信息,从而更准确地理解语义。
-
预训练与微调的结合:BERT通过大规模预训练获得通用语言表示,再通过微调适应特定任务,实现了高效迁移学习。
-
Transformer架构的优势:Transformer的自注意力机制能够处理长距离依赖关系,为模型提供了强大的表达能力。
反思与未来方向
尽管BERT及其衍生模型在NLP领域取得了显著成就,但仍存在一些挑战。例如,模型的计算资源需求较高,且在某些特定任务中的表现仍有提升空间。未来,研究者们可能会从以下几个方面进行探索:
-
开发更高效的预训练方法,降低计算成本。
-
探索跨语言、跨领域的通用模型。
-
结合知识图谱等外部资源,增强模型的理解能力。
结语
BERT及其相关模型的演进为自然语言处理领域带来了深远影响。通过不断优化和创新,预训练模型在理解和生成自然语言方面展现出了巨大潜力。对于研究者和开发者而言,深入理解这些模型的原理和应用场景,将有助于更好地推动NLP技术的发展。





