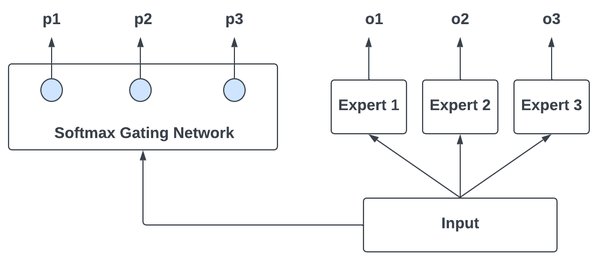
MoE混合专家模型的技术原理
MoE(Mixture of Experts)混合专家模型是一种基于多专家系统的深度学习架构。其核心思想是将复杂任务分解为多个子任务,每个子任务由专门的“专家”模型处理,最终通过门控机制(Gating Network)将各专家的输出进行加权整合。这种架构不仅能够提高模型的灵活性和适应性,还能显著降低计算资源的消耗。


MoE的优势与创新
MoE模型的最大优势在于其高效性和可扩展性。以昆仑万维科技公司发布的“天工大模型3.0”为例,该模型采用4000亿级参数的MoE架构,具有以下显著特点:
-
参数数量大:通过多专家系统的设计,模型能够处理更大规模的数据,适用于复杂任务。
-
运行效率高:MoE架构通过动态选择专家模型,减少不必要的计算,提升整体效率。
-
应用场景广:MoE模型在自然语言处理、计算机视觉、推荐系统等多个领域表现出色,展现了强大的通用性。

MoE在AI领域的应用
MoE模型在人工智能领域的应用前景广阔。以下是其主要应用场景:
-
自然语言处理(NLP):MoE模型在文本生成、机器翻译、情感分析等任务中表现出色,能够处理多语言、多领域的复杂文本数据。
-
计算机视觉:在图像识别、视频生成等任务中,MoE模型通过多专家系统的设计,能够高效处理高维数据。
-
推荐系统:MoE模型通过动态选择专家模型,能够为用户提供更精准的个性化推荐,提升用户体验。
MoE的未来发展方向
随着人工智能技术的不断进步,MoE模型在未来将迎来更多创新与突破。以下是几个值得关注的方向:
-
多模态融合:将MoE模型应用于多模态数据(如文本、图像、音频等)的处理,进一步提升模型的通用性和适应性。
-
自监督学习:结合自监督学习技术,MoE模型能够在无监督或弱监督的情况下进行训练,降低数据标注成本。
-
智能体协作:通过多智能体系统的设计,MoE模型能够在复杂环境中实现智能体之间的协作与优化。
结语
MoE混合专家模型作为人工智能领域的重要技术革新,正在推动大模型技术的发展与应用。昆仑万维科技公司的“天工大模型3.0”展示了MoE架构的强大潜力,未来这一技术将在更多领域发挥重要作用,为人工智能的普及与发展注入新的动力。






