在人工智能领域,推理模型的训练效率一直是研究的核心问题。近日,阶跃星辰与清华大学联合发布了Open Reasoner Zero (ORZ)模型,这一模型在推理训练领域取得了革命性突破,仅需1/30的训练步骤即可达到与DeepSeek-R1-Zero相同尺寸的蒸馏Qwen模型的性能。这一成果标志着AI训练效率的显著提升,为未来的AI发展开辟了新的可能性。
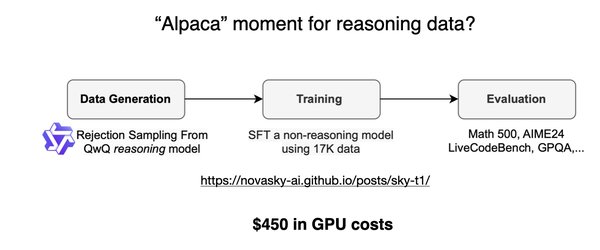
ORZ模型的训练效率优势
ORZ模型的核心优势在于其高效的训练方法。与传统的推理模型相比,ORZ在响应长度上仅需约17%的训练步骤即可赶上DeepSeek-R1-Zero 671B的性能。这一突破不仅节省了大量的计算资源,还大幅缩短了训练时间,为AI应用的快速迭代提供了有力支持。
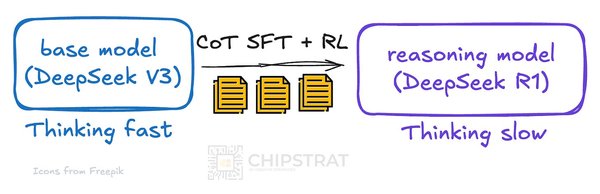
跨领域合作推动技术革新
ORZ模型的成功离不开阶跃星辰与清华大学的紧密合作。此外,AI领域的知名专家沈向洋、姜大昕和张祥雨等也深度参与了该项目。他们的专业知识和经验为ORZ模型的研发提供了重要支持,进一步推动了AI技术的创新与发展。

推理模型训练的挑战与解决方案
在推理模型的训练过程中,控制字符的使用和文本处理的方式对模型性能有着重要影响。例如,换行符( )和回车符( )在不同操作系统中的表现差异可能导致跨平台兼容性问题。ORZ模型通过优化训练流程和数据处理方式,有效解决了这些问题,提升了模型的稳定性和适用性。
未来展望
ORZ模型的发布不仅展示了AI训练效率的显著提升,也为未来的AI研究提供了新的方向。随着技术的不断发展,如何进一步优化推理模型的训练方法,将成为AI领域持续关注的重点。ORZ模型的成功经验将为后续研究提供宝贵的参考,推动AI技术向更高层次迈进。
Open Reasoner Zero (ORZ)模型的发布标志着推理模型训练领域的一次重大突破。通过高效训练方法和跨领域合作,ORZ为AI技术的发展注入了新的活力,也为未来的AI应用提供了更广阔的可能性。





