在人工智能领域,强化学习(RL)以其独特的学习方式和显著的应用潜力,正吸引着越来越多的研究者和企业的关注。最近,国内技术团队通过OpenReasonerZero(ORZ)项目,成功将DeepSeek-R1-Zero的训练步骤减少至原来的1/30,这一突破不仅提升了训练效率,还为AI大语言模型研究开辟了新方向。
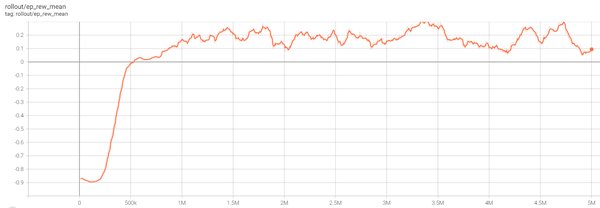
技术突破:训练步骤大幅减少
在原始的DeepSeek-R1-Zero模型中,训练过程需要极为复杂的参数设置和调优。而ORZ项目利用了更为简洁的PPO算法,经过大量实验后,团队发现使用GAE(Generalized Advantage Estimation)和适当的折扣因子设置,可以在模型推理任务中大幅度提升响应长度和基准性能。这一发现与复杂的奖励函数相对立,为AI模型的训练提供了新的思路。


“顿悟时刻”与模型涌现行为
值得一提的是,新方法在达到680步时,训练奖励值、反思能力和回答长度三者都出现了显著提升,类似于DeepSeek-R1-Zero研究中提到的“顿悟时刻”。这一现象提示研究者,模型在学习过程中可能存在关键的转折点,而对于该转折点的把握将是提升AI模型训练效果的重要环节。此外,团队强调,在训练过程中不依赖传统的基于KL的正则化技术,这一做法颠覆了当前学术界对于RLHF(Reinforcement Learning from Human Feedback)和推理模型的许多固有认识。
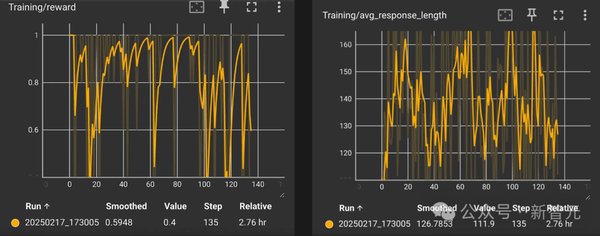
数据集的重要性与开源精神
在OpenReasonerZero的训练中,使用了大规模且多样化的数据集,这一策略使得模型能够在各类任务中表现出色。尤其是对于较小规模的数据集,例如MATH等,这些数据集虽然有限,但一旦达到平台期,其性能提升的空间将受到局限。因此,精心设计的数据集,尤其是那些能够不断引发学习效应的数据,显得尤为重要。同时,研究者也发现,在以Qwen2.5-Base-7B作为基础模型的测试中,各类基准测试在一定的训练周期内都展现出相似的奖励与响应长度突增现象,进一步支持了模型涌现行为的假设。
这一开源项目自发布以来,便引起了广泛关注,48小时内便收获了700多颗星星。所有训练代码、数据和相关文献都以100%的开源形式发布,极大的降低了AI学习资源的获取门槛。使用MIT许可证也体现了团队对共同进步的重视与开放态度。值得注意的是,OpenReasonerZero的出现无疑将在国内外AI研究中引发更多的讨论与探索,未来可能会为其他基于RL的模型提供强有力的参考。
未来展望
开源软件的迅速崛起正重新定义技术共享的方式和理念,特别是在AI领域,研究者们越来越注重于合作与开放。当前的工业界与学术界都对OpenReasonerZero表现出浓厚的兴趣,姜大昕在最近的阶跃星辰生态开放日上也提到了这一研究的进展,表示该项目仍在不断完善中,后续可能会有更多的成果发布。因此,研究者、开发者以及AI爱好者们都应密切关注这一领域的发展动态,以便及时把握新技术带来的机遇。在AI迅速发展的今天,谁能够抓住机遇,谁就能在未来的竞争中立于不败之地。
总的来看,OpenReasonerZero突破了传统RL训练方法的界限,以更简单有效的方式实现高性能,未来或将推动强化学习在更广泛应用场景中的落地。这不仅是对当前深度学习模型训练的一次革新,也为未来的人工智能研究指明了新的方向。希望更多团队能够借助这一开源平台,加速自身的研究和应用,推动人工智能技术的不断前进。











