大语言模型(LLMs)在自然语言处理领域取得了显著进展,但其通用性在某些特定场景下可能无法满足需求。例如,当任务涉及专有数据或需要高度专业化的知识时,通用模型的表现往往不尽如人意。为了解决这一问题,强化学习与人类反馈(Reinforcement Learning from Human Feedback, RLHF)技术应运而生,成为优化大语言模型的重要工具。
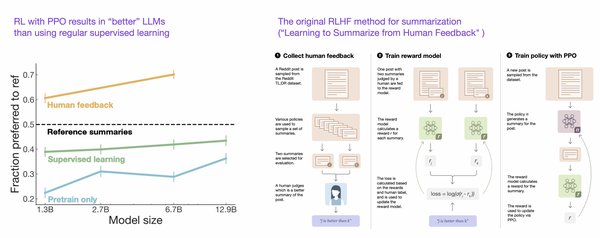
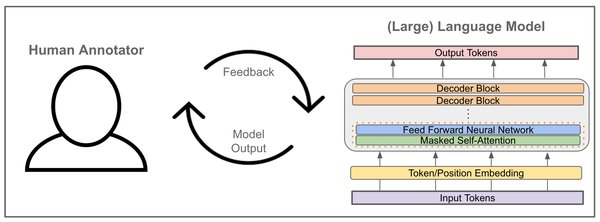
什么是RLHF?
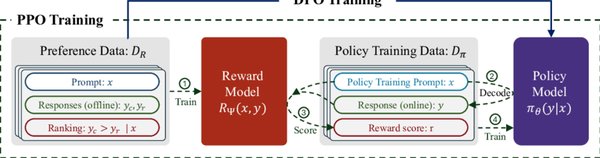
RLHF是一种通过人类反馈数据来优化大语言模型的强化学习技术。其核心思想是利用人类标注的偏好数据训练奖励模型,并通过奖励模型指导模型的优化过程。RLHF的目标是使模型生成的响应更符合人类偏好,减少模型幻觉(即生成不准确或无意义的内容)和毒性(即生成不当或有害的内容)。

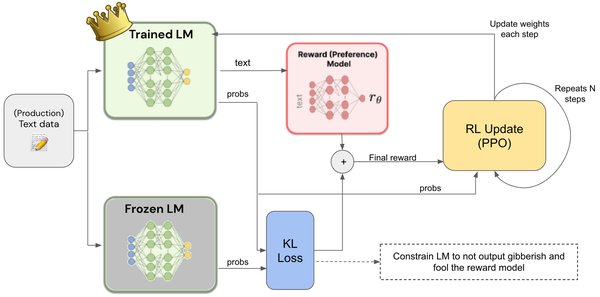
RLHF的关键步骤
RLHF的实现过程可以分为以下几个关键步骤:
-
收集偏好数据集:人类标注员对不同模型生成的响应进行评分,标注出哪些响应更符合人类偏好。偏好数据集的格式通常为
{输入文本, 候选响应1, 候选响应2, 人类偏好}。 -
训练奖励模型:利用偏好数据集训练一个回归模型,该模型能够为模型生成的响应打分,分数越高表示响应质量越好。
-
强化学习优化:将奖励模型作为奖励函数,通过强化学习算法(如近端策略优化,PPO)优化大语言模型。在强化学习过程中,模型不断调整其策略,以生成能够最大化奖励分数的响应。
RLHF的优势与应用
RLHF技术在多个领域展现了显著优势:
-
减少模型幻觉:通过人类反馈数据,RLHF能够有效减少模型生成不准确或无意义内容的情况。
-
降低毒性内容:RLHF使模型生成的响应更符合社会规范和道德标准,减少不当或有害内容的生成。
-
提升生成质量:RLHF能够显著提升模型生成内容的准确性和可接受性,使其在对话系统、文本生成、情感分析等领域表现更佳。
RLHF的挑战与未来发展
尽管RLHF技术取得了显著成果,但其也面临一些挑战:
-
数据需求高:RLHF需要大量人类标注的偏好数据,数据收集和标注成本较高。
-
计算资源消耗大:强化学习过程的计算资源需求较高,特别是在大规模模型上应用时。
为应对这些挑战,研究者们正在探索替代方案,如基于AI反馈的强化学习(Reinforcement Learning from AI Feedback, RLAIF)和直接偏好优化(Direct Preference Optimization, DPO)。这些技术旨在减少对人类标注数据的依赖,同时降低计算成本。
结论
RLHF技术通过结合人类反馈和强化学习,为大语言模型的优化提供了强有力的工具。它不仅能够显著提升模型生成内容的质量,还能减少模型幻觉和毒性,使其在更多场景中展现卓越表现。随着技术的不断发展,RLHF及其衍生技术将在自然语言处理领域发挥越来越重要的作用。







