DeepSeek-V3是一款由中国杭州的AI初创公司DeepSeek开发的生成式AI模型,凭借其低成本和高性能在全球范围内引起了广泛关注。这款模型不仅在多个基准测试中超越了OpenAI的GPT-4o,还以极低的成本实现了商业化应用,成为国产科技在AI领域的一次重要突破。
技术架构与创新
DeepSeek-V3的核心技术之一是Mixture-of-Experts(MoE)架构。这种架构允许模型在处理不同任务时,动态选择最相关的“专家”模块进行计算,从而显著提高了计算效率。与传统的单一模型相比,MoE架构能够在不增加计算资源的情况下,提升模型的多样性和准确性。
此外,DeepSeek-V3还采用了Multi-head Latent Attention机制。这一技术通过压缩和共享注意力机制中的关键值,进一步优化了计算效率,使得模型在处理大规模数据时能够保持高效。

性能表现
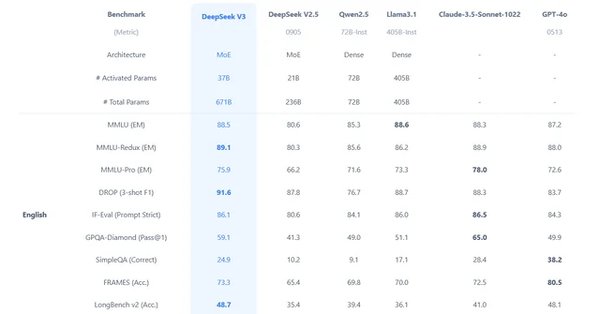
DeepSeek-V3在多个基准测试中表现出色。例如,在英语知识测试MMLU-Pro中,DeepSeek-V3的得分为75.9,略低于Claude-3.5(78.0),但明显高于GPT-4o(72.6)。在数学和中文能力测试中,DeepSeek-V3更是以显著优势领先于其他模型。此外,在编程能力测试中,DeepSeek-V3在7项测试中有5项超越了GPT-4o和Claude-3.5。
应用场景
DeepSeek-V3的广泛应用场景包括:
-
内容创作:DeepSeek-V3能够高效生成高质量的文本内容,适用于新闻写作、广告文案等领域。
-
虚拟助手:凭借其快速的响应速度和高效的上下文处理能力,DeepSeek-V3成为虚拟助手的理想选择。
-
教育:DeepSeek-V3在数学和中文能力上的优势,使其在在线教育平台中具有广泛的应用前景。
行业影响
DeepSeek-V3的成功不仅展示了国产科技在AI领域的竞争力,还对整个AI行业产生了深远影响。其低成本高性能的特点,使得更多企业和开发者能够使用先进的AI技术,推动了AI技术的普及和应用。
结论
DeepSeek-V3作为一款低成本高性能的生成式AI模型,凭借其创新的技术架构和卓越的性能表现,成为了AI领域的一颗新星。未来,随着技术的不断进步和应用场景的拓展,DeepSeek-V3有望在全球AI市场中占据更加重要的地位。




