深度学习:人工智能的技术支柱
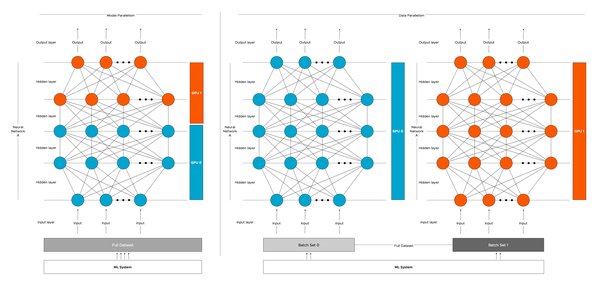
深度学习作为人工智能的重要分支,通过多层次的神经网络结构,能够处理复杂的非线性问题。其核心在于通过增加隐藏层数来提升模型的表达能力,从而解决更复杂的任务。然而,深度学习的实现并非易事,其背后需要强大的计算能力和海量的数据支持。
硬件的发展,尤其是GPU(图形处理单元)和GPGPU(通用图形处理单元)的出现,为深度学习的计算需求提供了重要支持。例如,NVIDIA的GPU因其并行计算能力而成为深度学习的主流选择。此外,Google的TPU(张量处理单元)等专用芯片也在推动深度学习技术的进一步发展。

AlexNet:ImageNet挑战赛的里程碑
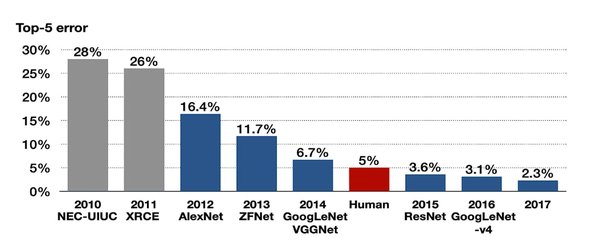
在深度学习的应用历史中,AlexNet无疑是一个里程碑。作为2012年ImageNet挑战赛的冠军,AlexNet首次证明了深度学习在计算机视觉领域的巨大潜力。AlexNet采用了深度卷积神经网络结构,其参数数量高达约6000万个,这在当时是一个惊人的数字。
根据“巴尼叔叔的规则”,深度学习模型需要的数据量通常是参数数量的10倍。因此,AlexNet的训练需要约6亿条数据。这一规则不仅揭示了深度学习对数据的依赖,也为后续模型的设计提供了重要参考。
Transformer与跨领域应用
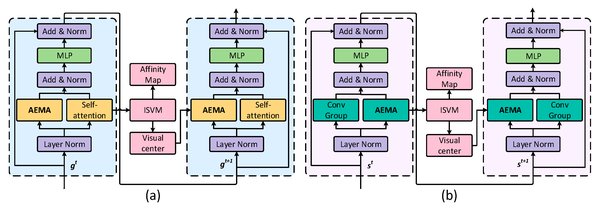
2017年,Transformer模型的推出为自然语言处理(NLP)和计算机视觉带来了革命性变化。Transformer的自注意力机制使其能够高效处理长序列数据,成为GPT系列模型的基础。例如,GPT-2的Tokenizer虽然在英语上表现优异,但在处理其他语言(如缅甸的Shan语)时,可能需要多达15倍的Token数量。
Transformer的成功不仅限于NLP领域,其架构还被广泛应用于计算机视觉任务,进一步推动了AI技术的跨领域融合。
AGI的创新步伐:ChatGPT与o1模型
2024年,ChatGPT公司发布了最新的大型语言模型o1,标志着通用人工智能(AGI)的探索进入新阶段。尽管o1尚未在所有任务上超越人类,但其在大多数任务上的表现已优于大多数人类。这一成就引发了关于AGI定义的广泛讨论,同时也为AI的未来发展指明了方向。
从AlexNet的突破到o1的创新,深度学习技术不断推动人工智能的边界。未来,随着硬件和算法的进一步发展,AGI的实现或许不再遥不可及。







