注意力机制的起源
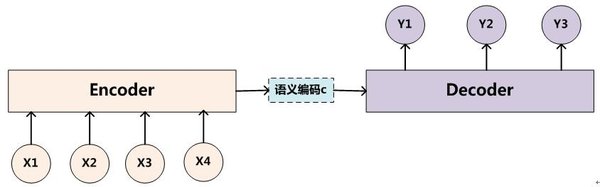
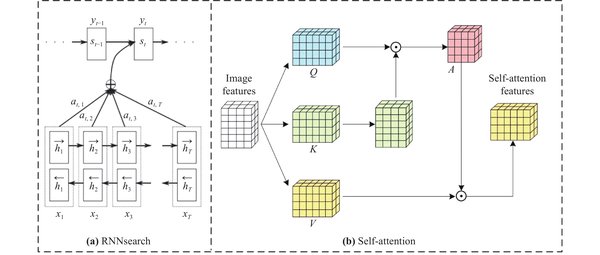
注意力机制并非2017年Transformer论文的首创,而是可以追溯到2014年Bengio实验室的研究。当时,Dzmitry Bahdanau在实习期间提出了一种简化方案,旨在解决神经机器翻译中的长距离依赖问题。这一方案后来被称为“RNNSearch”,并在Yoshua Bengio的建议下更名为“注意力机制”。
从RNNSearch到Transformer
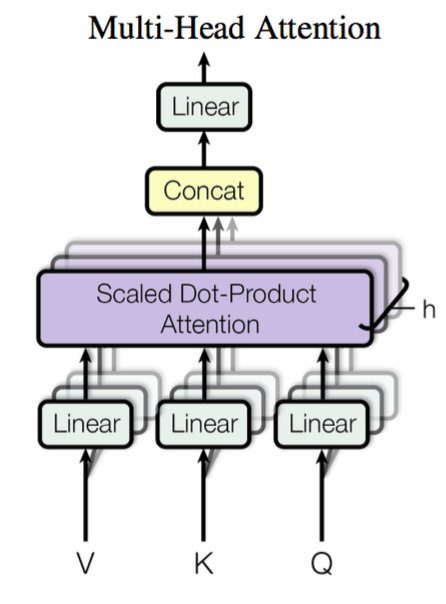
RNNSearch的核心思想是通过动态计算源序列和目标序列之间的权重,使模型能够“聚焦”于最相关的信息。这一机制显著提升了神经机器翻译的性能,并成为后续研究的基石。2017年,Transformer模型的提出进一步将注意力机制推向巅峰。Transformer摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),完全依赖注意力机制,实现了更高的并行化效率和更快的训练速度。
Transformer的性能突破
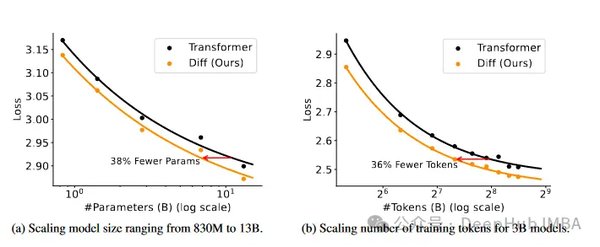
Transformer在机器翻译任务中展现了卓越的性能。例如,在WMT 2014英语到德语的翻译任务中,Transformer模型取得了28.4的BLEU分数,比当时的最佳模型提高了2个BLEU分数。在英语到法语的翻译任务中,Transformer更是创下了41.0的BLEU分数,成为新的单模型标杆。这些成就证明了注意力机制在序列建模中的强大潜力。
注意力机制的多语言挑战
尽管注意力机制在英语任务中表现出色,但在其他语言中仍面临挑战。例如,GPT-2的分词器在处理某些语言时,可能需要比英语多15倍的token。即使是葡萄牙语和德语,其token数量也比英语高出50%。这表明,注意力机制在不同语言中的优化仍需进一步研究。
澄清误解与未来展望
关于Transformer的灵感来源,有一种误解认为其受到科幻电影《降临》的启发。然而,Transformer的设计更多是基于2014年Attention机制的研究成果。未来,随着多语言模型的发展,注意力机制有望在更广泛的语言任务中实现突破,为全球化的自然语言处理提供支持。
通过回顾注意力机制的起源与演变,我们不仅能够更好地理解其在深度学习中的重要性,也能为未来的研究提供宝贵的启示。




