在人工智能领域,模型的高效压缩与加速一直是研究的核心课题。DeepSeek公司最新推出的知识蒸馏加速框架,通过一系列创新技术,为这一领域带来了突破性进展。该框架不仅在性能与效率之间实现了完美平衡,还为开发者提供了简单易用的配置方案,助力AI技术的大规模落地。
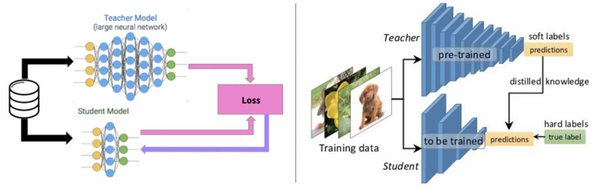
创新技术:分层蒸馏与动态温度调节
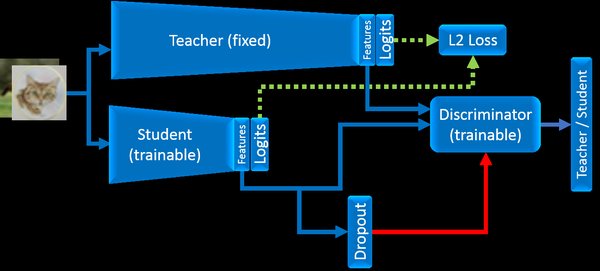
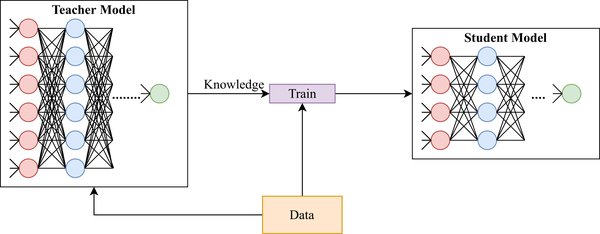
DeepSeek知识蒸馏加速框架的核心在于其首创的分层蒸馏策略和动态温度调节机制。分层蒸馏策略通过多阶段蒸馏路径,逐步将教师模型的知识迁移到学生模型中,确保知识传递的高效性与完整性。动态温度调节机制则通过自适应调整蒸馏过程中的温度参数,优化知识迁移的效果,进一步提升模型的性能。
在实际应用中,该框架在BERT模型压缩任务中表现出色:
-
推理速度提升4.8倍:通过优化模型结构与计算路径,显著加速推理过程。
-
内存占用降低至32%:采用高效的内存管理策略,大幅减少资源消耗。
-
训练时间压缩至原版的1/5:通过分层蒸馏与动态温度调节,显著缩短训练周期。
渐进式知识迁移:多阶段路径实现高效压缩
DeepSeek框架的另一大亮点是其渐进式知识迁移算法。该算法通过将知识迁移过程划分为多个阶段,逐步将教师模型的复杂知识传递到学生模型中。这种多阶段路径不仅提高了知识传递的效率,还确保了学生模型在压缩后仍能保持95%的性能。
在实际部署中,开发者可以通过简单配置启用该功能:
-
从小型任务开始测试:建议开发者从小规模任务入手,逐步验证框架的性能与稳定性。
-
逐步扩展到复杂场景:在小型任务验证成功后,逐步将框架应用于更复杂的AI模型压缩任务。
-
配合混合精度计算:部署时结合混合精度计算技术,可进一步提升能效比,实测显示可降低38%的GPU内存占用。
技术生态:推动国产AI技术普及
DeepSeek知识蒸馏加速框架的推出,不仅为AI模型压缩提供了创新解决方案,还推动了国产AI技术生态的发展。中国电子多款产品已全面适配DeepSeek框架,包括长城擎天GF7280 V5 AI训推一体机、中电金信AI产品、中国软件熵舟数智底座等。这些适配工作为行业用户提供了大模型智能应用落地的一体化解决方案,加速了国产AI技术的普及与应用。
未来展望:AI模型压缩的新篇章
DeepSeek知识蒸馏加速框架的成功,标志着AI模型压缩技术迈入了一个新阶段。未来,随着技术的不断演进,该框架有望在更多领域发挥重要作用,为AI技术的规模化应用提供强有力的支持。DeepSeek的创新实践,不仅展示了中国在AI领域的强大实力,也为全球AI技术的发展提供了宝贵经验。
通过分层蒸馏、动态温度调节与渐进式知识迁移,DeepSeek知识蒸馏加速框架为AI模型的高效压缩与加速开辟了新的道路。无论是开发者还是行业用户,都可以从这一创新技术中受益,共同推动AI技术的未来发展。







