在人工智能领域,模型训练的效率与性能一直是开发者关注的焦点。DeepSeek公司最新推出的知识蒸馏加速框架,通过创新的分层蒸馏策略和动态温度调节机制,为AI模型训练带来了革命性的变革。
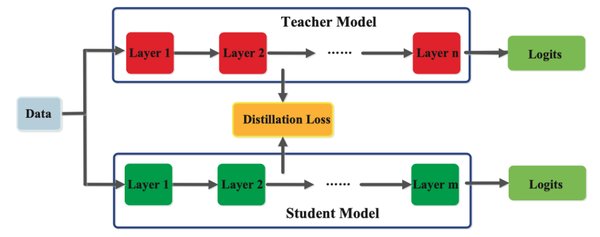
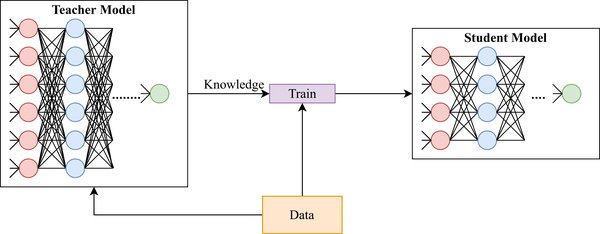
分层蒸馏策略
DeepSeek的知识蒸馏框架采用了分层蒸馏策略,通过多阶段蒸馏路径实现从教师模型到学生模型的高效知识传递。这种策略不仅显著降低了训练时间,还保持了95%的模型性能。具体来说,分层蒸馏策略包括以下几个关键步骤:
-
初始化阶段:教师模型和学生模型同时进行初始化,确保两者的基础结构一致。
-
知识迁移阶段:通过动态温度调节机制,逐步将教师模型的知识迁移到学生模型。
-
优化阶段:利用渐进式知识迁移算法,进一步优化学生模型的性能。
动态温度调节机制
动态温度调节机制是DeepSeek框架的核心技术之一。该机制通过实时调整知识蒸馏过程中的温度参数,确保知识迁移的高效性和稳定性。具体来说,动态温度调节机制具有以下优势:
-
自适应调整:根据模型训练的进度和性能,自动调整温度参数,确保知识迁移的平滑过渡。
-
性能优化:通过精确的温度控制,最大限度地保留教师模型的知识,同时提升学生模型的推理速度。
-
资源节约:动态温度调节机制显著降低了GPU内存占用,实测显示可降低38%的GPU内存占用。
实际应用与效果
在实际应用中,DeepSeek的知识蒸馏框架在BERT模型压缩任务中表现尤为突出。具体效果如下:
-
推理速度提升:推理速度提升4.8倍,显著提高了模型的实际应用效率。
-
内存占用降低:内存占用降低至32%,使得模型在资源有限的环境下也能高效运行。
-
训练时间压缩:训练时间压缩至原版的1/5,大大缩短了模型开发的周期。
部署建议
对于开发者而言,DeepSeek的知识蒸馏框架提供了简单易用的配置选项。建议从小型任务开始测试,逐步扩展到复杂场景。此外,配合混合精度计算可以进一步提升能效比,确保模型在高效运行的同时,最大限度地节约资源。
总结
DeepSeek的动态温度调节机制和分层蒸馏策略,为AI模型训练带来了前所未有的效率与性能提升。通过这一创新技术,开发者可以在保持模型高性能的同时,显著降低训练时间和资源消耗,为人工智能的广泛应用奠定了坚实的基础。






