数据归因:机器学习中的关键问题
在ICML 2024上,Andrew Ilyas及其团队在讲座“Data Attribution at Scale”中,深入探讨了数据归因(Data Attribution)问题。数据归因旨在理解训练数据对模型行为的影响,这一问题在生成式人工智能(GenAI)和大语言模型(LLM)的背景下变得尤为重要。随着模型规模的扩大和复杂性的增加,追踪数据对模型决策的贡献成为了一项关键挑战。
数据归因的研究不仅有助于提升模型的透明度和可解释性,还为模型健壮性和选择性遗忘(Unlearning)等前沿应用提供了新的思路。例如,在模型编辑和选择性遗忘场景中,精确的数据归因可以帮助识别并移除特定数据对模型的影响,从而满足隐私保护和合规性需求。
多模态模型中的数据归因挑战
尽管数据归因在语言模型中已经取得了一定的进展,但在多模态模型中,这一领域仍处于早期阶段。多模态模型结合了视觉、文本等多种模态的信息,其内部机制更加复杂,为数据归因研究带来了新的挑战。
目前,多模态模型的数据归因研究主要集中在以下几个方面:
-
扩散变换器内部层的解释:理解扩散变换器在任务(如模型编辑)中的内部工作机制。
-
超越简单任务的应用:将数据归因的洞察扩展到视觉问答(VQA)和图像生成之外的任务。
-
序列化模型编辑技术:开发适用于多模态模型的序列化编辑方法,包括扩散模型和多模态语言模型。
-
稀疏自编码器的应用:探索稀疏自编码器及其变体在多模态模型控制和引导中的有效性。
这些挑战的解决将有助于提升多模态模型的透明度和可控性,为数据归因和选择性遗忘提供更强大的技术支持。
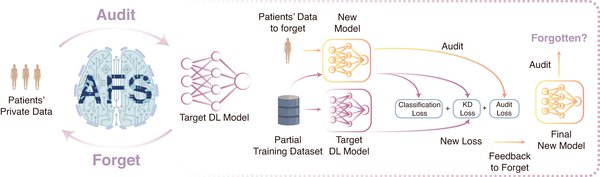
选择性遗忘:数据归因的核心应用
选择性遗忘(Unlearning)是数据归因的一个重要应用场景。随着数据隐私法规的日益严格,模型需要具备“遗忘”特定数据的能力,以保护用户隐私并满足合规性要求。数据归因技术可以帮助识别哪些训练数据对模型行为产生了显著影响,从而为选择性遗忘提供精确的目标。
例如,在多模态模型中,数据归因可以用于追踪特定图像或文本对模型生成结果的影响。通过移除或修改这些数据,模型可以“遗忘”相关信息,从而降低隐私泄露的风险。
未来展望
数据归因和选择性遗忘的研究仍处于快速发展阶段,尤其是在多模态模型的背景下,还有许多开放性问题需要解决。未来的研究方向包括:
-
开发更高效的数据归因方法,以应对大规模多模态模型的复杂性。
-
探索数据归因在统一视觉-文本理解和生成模型中的应用。
-
结合机制解释(Mechanistic Interpretability)技术,提升多模态模型的透明度和可控性。
随着技术的不断进步,数据归因和选择性遗忘将在机器学习领域发挥越来越重要的作用,为模型的透明度、健壮性和隐私保护提供强有力的支持。








