在计算机视觉领域,自监督学习(Self-Supervised Learning, SSL)正逐渐成为主流。BEiT(Bidirectional Encoder representation from Image Transformers)是微软提出的一种基于自监督预训练的视觉模型,它将BERT的成功经验应用于视觉领域,展示了在速度、内存占用和超参数方面的优势,并能够复用NLP预训练框架和经验,扩展ViT的规模,释放算力和无标注数据的潜力。
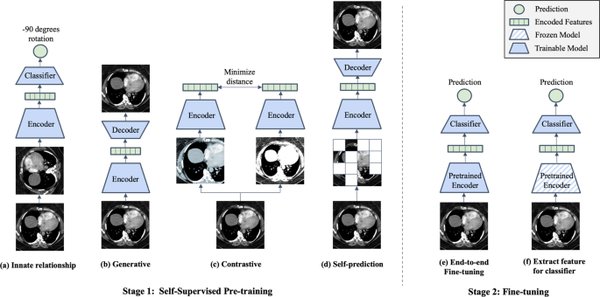
BEiT的核心思想
BEiT的核心思想是通过Masked Image Modeling(MIM)进行训练,类似于BERT的掩码自监督学习方法。具体来说,BEiT在训练时会随机遮挡一部分图像的Patch,然后让模型去预测被遮挡的部分。这种方法能让Transformer充分学习图像的局部和全局特征,提高泛化能力。
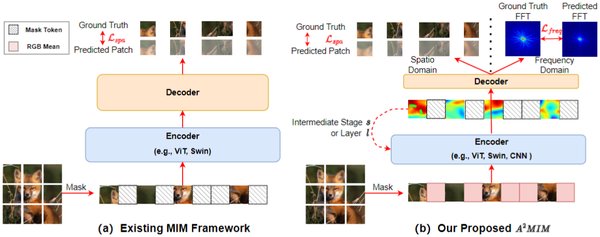
BEiT的关键技术
-
Masked Image Modeling(MIM):BEiT采用MIM方法,将输入图像划分为Patch,随机遮挡部分Patch,使用预训练的视觉词表来预测被遮挡部分的正确Token,并最小化预测Token和真实Token之间的损失。
-
视觉词表(Visual Tokenizer):BEiT采用VQ-VAE(Vector Quantized Variational AutoEncoder)作为视觉Token生成器,将连续的图像特征映射到离散的视觉词表,类似于NLP领域的词向量。
-
ViT Backbone:BEiT采用Vision Transformer(ViT)作为主干网络,直接基于Transformer结构进行图像建模,配合MIM训练方式,使得BEiT能够高效学习图像特征。

BEiT的优势
BEiT在图像分类、目标检测、分割等任务上取得了比ViT更强的性能。其核心创新在于Masked Image Modeling(MIM)+视觉词表,这使得BEiT在无标签数据上能进行高效预训练。此外,BEiT能够复用NLP预训练框架和经验,扩展ViT的规模,释放算力和无标注数据的潜力。
BEiT的未来展望
未来,BEiT可能会与更强的视觉Transformer(如Swin Transformer)结合,进一步提升自监督视觉学习的能力。自监督学习是解决Google大规模内部标注数据集JFT-300M限制的唯一选项,BEiT在这一领域的突破将为计算机视觉带来更多可能性。
通过自监督学习和Transformer的结合,BEiT不仅在性能上取得了显著提升,还为视觉领域的未来发展开辟了新的道路。随着技术的不断进步,BEiT有望在更多复杂任务中展现出其强大的潜力。




