自监督学习的崛起:AI模型训练的新范式
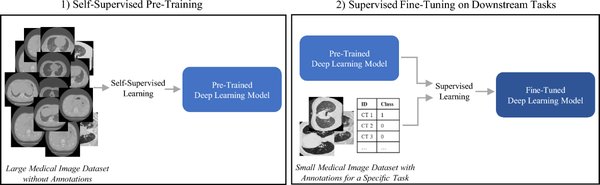
近年来,随着人工智能技术的飞速发展,模型训练的方法也在不断演进。传统的监督学习依赖大量人工标注数据,这不仅成本高昂,还限制了模型的泛化能力。在此背景下,自监督学习和强化学习逐渐成为研究热点。蚂蚁数科的两项研究成果分别入选了欧洲计算机视觉会议(ECCV)和国际机器学习大会(ICML),展示了这些方法在无需人工标注数据的情况下训练模型输出可信结果的能力。这些成果不仅具有学术价值,更将推动视频版权保护和智能问答等领域的创新。
自监督学习的核心优势
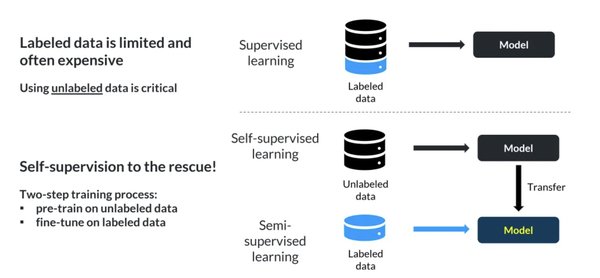
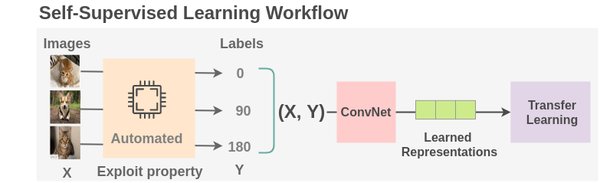
自监督学习的核心在于利用数据本身的结构和特性进行训练,而无需依赖外部标注。这种方法的优势在于:
-
降低数据成本:无需人工标注,显著减少了数据准备的时间和费用。
-
提升泛化能力:模型通过自我学习数据的内在规律,能够更好地适应多样化场景。
-
推动技术创新:自监督学习为AI模型的训练开辟了新路径,尤其在数据稀缺的领域具有重要价值。
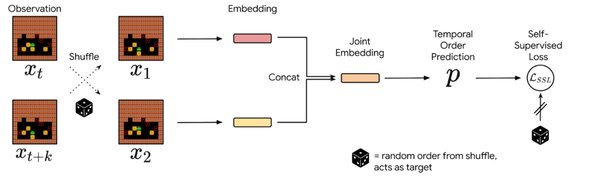
强化学习与自监督学习的结合
强化学习通过奖励机制引导模型优化行为,而自监督学习则通过数据的内在特性进行训练。两者的结合为AI模型训练提供了更强大的工具。以DeepSeek的R1模型为例,其通过纯强化学习实现了推理模型的训练,证明了即使没有过程监督数据,仅通过结果监督也能达到顶级性能。这一突破不仅展示了强化学习的潜力,也为自监督学习的应用提供了新思路。
应用场景:视频版权保护与智能问答
蚂蚁数科的研究成果将率先应用于视频版权保护和智能问答领域。在视频版权保护中,自监督学习可以帮助模型自动识别视频内容,检测侵权行为,而无需依赖人工标注。在智能问答领域,强化学习驱动的推理模型能够提供更精准、更自然的回答,提升用户体验。
未来展望:自监督学习的无限可能
自监督学习和强化学习的结合为AI模型训练开辟了新的可能性。未来,这些技术有望在更多领域实现突破,例如:
-
动态自适应推理:模型能够根据任务需求自主调整推理策略。
-
智能创新助手:通过自监督学习,模型可以辅助人类进行创造性工作,如写作、设计等。
-
自进化生态系统:模型能够通过自我学习和优化,构建动态进化的智能系统。
自监督学习和强化学习的结合不仅为AI模型训练提供了新范式,更将推动人工智能技术在更多领域的创新与应用。蚂蚁数科的研究成果正是这一趋势的缩影,标志着AI技术正迈向一个更加智能、更加自主的未来。




