近年来,随着人工智能和深度学习的快速发展,GPU作为提升计算性能的核心硬件之一,其市场需求不断攀升。然而,国内GPU产业在这一领域长期受到外国技术的限制,尤其是英伟达的CUDA几乎垄断了AI计算市场。在这样的背景下,DeepSeek技术的出现,为国产GPU产业带来了新的希望与挑战。


DeepSeek的CUDA优化能力
DeepSeek-R1作为一款前沿的AI模型,展现了在CUDA优化方面的强大潜力。根据斯坦福和普林斯顿的研究,DeepSeek-R1能够生成自定义CUDA内核,并在KernelBench框架下实现性能优化。尽管目前仅在不到20%的任务上超越PyTorch Eager基线,但其在GPU编程自动化方面的探索已迈出了重要一步。
DeepSeek-R1的优化能力主要体现在以下几个方面:
-
硬件感知优化:通过提供GPU硬件信息(如内存带宽、TFLOPS),DeepSeek-R1能够针对特定GPU(如A100、H100)进行优化。
-
内核生成技术:DeepSeek-R1尝试使用特定硬件的指令(如Tensor Core的wmma),尽管这些尝试尚未完全成熟,但展示了模型在硬件优化上的潜力。
-
迭代优化与反馈机制:通过KernelBench框架,DeepSeek-R1能够利用编译器反馈和执行错误信息,逐步改进生成的内核代码,显著提升了性能。
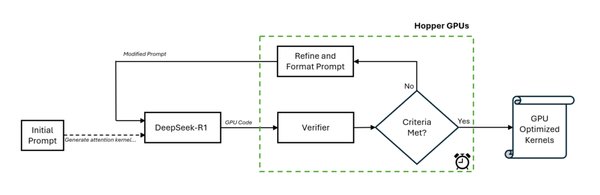
国产GPU生态的突破
DeepSeek技术的另一大亮点在于其为国产GPU生态带来的新思路。传统的国产GPU因缺乏完善的软件生态支持,尤其是CUDA兼容性,在实际应用中常常碰壁。DeepSeek通过直接与PTX指令集对接,绕开了部分CUDA框架的限制,为国产GPU提供了细粒度优化的可能性。
尽管这一技术路径需要开发者具备较高的硬件编程能力,并可能增加程序的复杂性,但它为国产GPU产业开辟了一条“稳妥”的技术路径。通过强化底层指令集和架构的创新,国产GPU厂商有望逐步打破对英伟达硬件的依赖,实现自主可控的发展。


算力瓶颈与开源生态
DeepSeek在实现用户爆发的同时,也面临着算力瓶颈的挑战。671B参数的MoE架构对显存要求极高,传统硬件难以负荷。然而,清华大学KVCache.AI团队推出的KTransformers开源项目,通过异构计算和专家卸载技术,成功在24G显存的消费级显卡上运行DeepSeek-R1满血版,实现了千亿级模型的“家庭化”。
这一技术突破不仅降低了硬件门槛,还为开源生态的发展提供了重要支持。通过整合Intel AMX指令集和CUDA Graph加速,KTransformers在CPU预填充和推理生成速度上实现了显著提升,为大规模AI任务提供了高效解决方案。
未来展望
DeepSeek技术的探索不仅关系到国产GPU产业的转折点,也为全球AI计算领域的发展提供了新的视角。未来,DeepSeek需要在以下几个方面持续发力:
-
技术迭代与优化:通过智能体工作流和微调技术,进一步提升CUDA内核生成的准确性与性能。
-
生态建设与合作:加快自主AI计算框架的研发,建设与CUDA相抗衡的完整软件生态。
-
政策支持与商业化落地:借助政策支持突破硬件生态依赖,同时平衡技术激进创新与商业化稳健落地。
DeepSeek的出现,或许只是国产GPU产业“小步快跑”的尝试,但其潜在的影响与希望值得我们期待。通过技术的不断迭代和生态的全面再造,国产GPU有望在全球AI竞争中占据一席之地,真正实现自主可控的发展之路。







