MoE架构:AI领域的革命性创新
2024年,AI领域在生成模型方面取得了重大进展,尤其是在大语言模型的架构创新上。Mixture-of-Experts(MoE,混合专家模型)架构成为焦点,DeepSeek等公司通过这一架构显著提升了模型的训练效率和性能。本文将深入探讨MoE架构的优势、DeepSeek的突破以及未来AI技术的前景。
MoE架构的核心优势
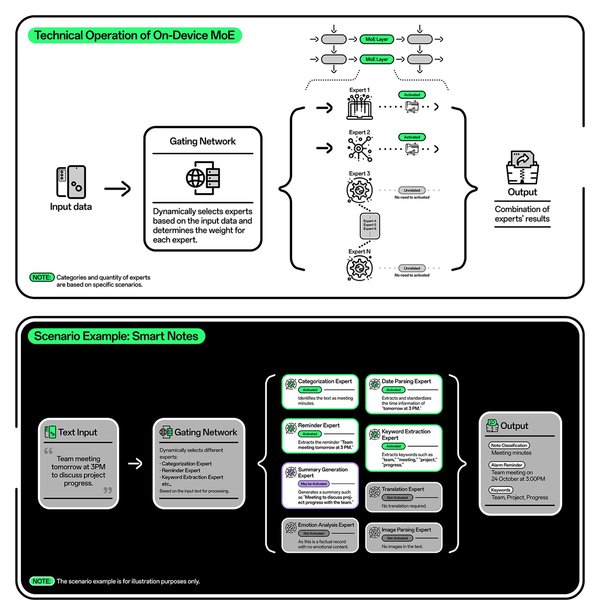
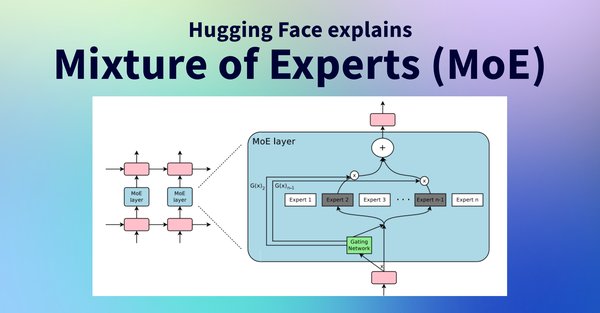
MoE架构的设计理念十分巧妙,它将一个复杂的问题分解、分类成多个更小、更易于管理的子问题,并由不同的专家网络分别处理。每个专家网络都有其专长领域,专门负责处理特定类型的任务或数据。例如,在处理自然语言时,有的专家擅长理解语法结构,有的则对语义理解更在行。
MoE架构的关键组成部分是门控机制。门控机制就像一个智能调度员,当输入数据进来时,它会对数据进行分析,然后根据数据的特点,把数据分配给最合适的专家网络进行处理。这种设计不仅提高了计算效率,还降低了能耗,因为每次只激活部分专家网络,而不是让整个模型的所有参数都参与计算。

DeepSeek的MoE架构创新
DeepSeek在MoE架构上的创新主要体现在以下几个方面:
-
负载均衡优化:MoE架构在训练过程中存在负载均衡问题,导致训练不稳定。DeepSeek-V2引入了额外的损失函数(设备级平衡损失和通信平衡损失)来让模型在训练中自主控制不同设备间的平衡,从而提高了训练效率和稳定性。
-
无令牌丢失:DeepSeek-V3在训练和推理过程中保持了无令牌丢失,确保了模型在处理连续任务时能够保持连续的处理,从而提高了模型的性能和稳定性。
-
MLA技术:DeepSeek还开发了Multi-Head Latent Attention(MLA,多头潜注意力)技术,通过低秩联合压缩键值(Key-Value),大幅减少所需的缓存容量,降低了计算复杂度和显存占用。
MoE与Transformer的完美结合
MoE架构和Transformer架构并不是孤立存在的,它们就像一对默契十足的搭档,相互融合,共同发挥出更强大的威力。一种常见的融合方式是,MoE架构中的稀疏MoE层替换Transformer模型中的前馈网络(FFN)层。在这种融合架构中,MoE层里的各个专家网络就像Transformer的“智囊团”,专门负责处理不同类型的输入数据。
这种融合方式的优势十分明显。一方面,MoE架构的引入使得模型在处理复杂任务时,能够根据不同的数据特点,调用不同的专家网络,从而提高了模型的准确性和鲁棒性。另一方面,Transformer架构的自注意力机制能够让模型更好地捕捉数据中的长距离依赖关系,理解上下文信息,为MoE层的专家网络提供更全面、准确的输入。
未来展望
随着技术的不断进步,我们有理由期待,在更多复杂的任务和场景中,MoE架构与Transformer架构的结合能够创造出更强大、更智能的AI系统,推动自然语言处理、计算机视觉、医疗、金融等各个领域的发展。DeepSeek等公司的创新不仅为AI领域带来了新的突破,也为未来的技术发展指明了方向。
2025年,我们可能会看到更多关于中国模型的崛起、训练效率的提升以及视频生成等新领域的突破。DeepSeek CEO梁文峰强调了开源社区和创新团队的核心竞争力,这无疑将为AI技术的进一步发展提供强大的动力。