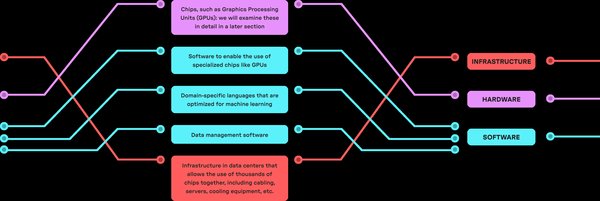
大模型发展的核心挑战:数据与算力
当前,大模型的发展正面临两大核心挑战:数据与算力。无论是OpenAI还是国产大模型,数据瓶颈始终是一个难以回避的问题。高质量、多样化的数据是训练大模型的基础,但现实中数据的获取与整合往往面临诸多限制。与此同时,算力的消耗也随着模型规模的扩大而急剧增加,成为制约大模型发展的另一大瓶颈。
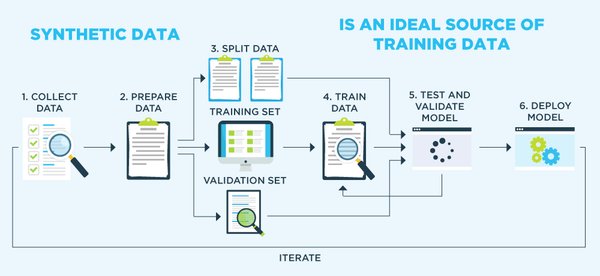
合成数据:突破数据瓶颈的关键
合成数据被认为是解决数据瓶颈的重要方向。商汤的Piccolo2模型正是这一领域的杰出代表。通过利用合成数据,Piccolo2模型能够生成大量负样本,从而显著降低误检测率与误识别率,提升模型的泛化能力。在性能评测中,Piccolo2甚至超越了OpenAI的SOTA水平,展现了合成数据在大模型训练中的巨大潜力。
合成数据的应用不仅限于模型训练,还在制造业等领域展现出广阔前景。例如,英伟达的Omniverse平台通过整合制造业数据,构建数字孪生工厂,为人型机器人仿真模拟提供支持。然而,目前中国制造业数据仍处于孤岛状态,数据聚合问题亟待解决。

算力瓶颈与未来方向
算力问题同样不容忽视。大模型的训练需要消耗大量算力,未来甚至可能达到十万块GPU甚至百万块的级别。这不仅对能源供应提出挑战,也对芯片技术提出了更高要求。未来,芯片技术可能从算力翻倍转向能效翻倍,通过工程化手段优化算力使用效率。
商汤在算力领域的布局采取双轨并行策略:一方面,通过科研领域的大规模算力集群(如上海临港的超大规模AIDC)推动基础研究;另一方面,探索技术领域的节能优化方案,例如在神经网络训练中仅激活部分计算资源。
未来AI基础设施的竞争
未来,AI基础设施的竞争将集中在超级AI计算集群与合成数据的应用上。随着合成数据量的成倍增长,模型的参数量可能达到数十万亿甚至百万亿级别。与此同时,各国在AI算力领域的投入也将持续加大,推动全球AI技术的前沿突破。
结论
合成数据与算力优化是大模型发展的两大关键方向。商汤的Piccolo2模型通过合成数据提升性能,展现了国产AI技术的创新实力。未来,随着超级AI计算集群的普及与合成数据的广泛应用,大模型将在更多领域实现突破,推动AI技术的普惠化与产业化。