
VLM-R1:从文本到视觉的跨模态飞跃
近年来,人工智能在文本处理领域取得了显著进展,但如何将这种能力扩展到视觉语言领域,一直是研究的热点。开源项目VLM-R1的出现,标志着这一领域的重大突破。VLM-R1成功地将DeepSeek的R1方法从纯文本领域迁移到视觉语言领域,实现了多模态图像识别能力的新突破。
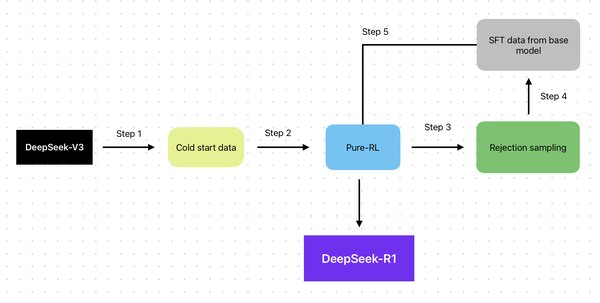
DeepSeek R1方法的创新核心
DeepSeek的R1方法最初是为了解决大语言模型(LLMs)在推理能力上的局限性而设计的。与传统的统计模型不同,R1通过强化学习技术,赋予模型“思考”的能力。这种能力不仅体现在解决复杂任务时的高效性,还体现在模型的自我反思与迭代过程中。
R1模型的核心特点包括:
-
推理能力:模型能够“思考”问题,而不仅仅是预测下一个最可能的词。
-
自我反思:在解决任务时,模型会重新评估初始方法,形成“顿悟时刻”。
-
链式思维:通过链式思维机制,模型能够逐步解决复杂任务。
-
拟人化表达:模型使用第一人称代词(如“我”)进行自我对话,甚至会在回答问题时表现出“犹豫”。
这些特点使得R1方法在编码、数学和逻辑推理等领域表现出色,而VLM-R1的成功迁移,进一步证明了这一方法的通用性和强大潜力。

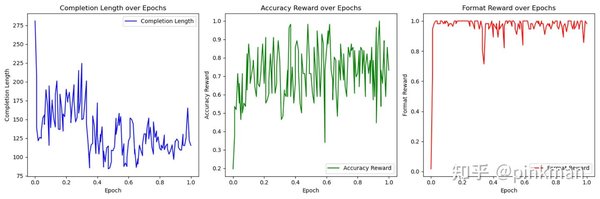
VLM-R1:多模态图像识别的新标杆
VLM-R1项目将R1方法从文本领域扩展到视觉语言领域,实现了多模态图像识别能力的新突破。以下是VLM-R1的几大亮点:
-
多场景适应:VLM-R1能够举一反三,适应多种场景和任务,而无需针对每个任务进行专门训练。
-
跨模态迁移:通过将R1方法应用于视觉语言模型,VLM-R1实现了文本与图像的深度融合。
-
开源共享:该项目已在GitHub上线,并迅速登上热门趋势榜,吸引了全球开发者和研究者的关注。
开源生态的推动力
VLM-R1的成功离不开开源生态的支持。通过GitHub平台,开发者可以轻松获取项目的源代码和相关资源,并参与到项目的改进与优化中。这种开放协作的模式,不仅加速了技术创新的步伐,也为多模态图像识别领域的发展注入了新的活力。
未来展望
VLM-R1的出现,标志着多模态图像识别领域的一次革命性突破。随着技术的不断迭代和应用场景的拓展,VLM-R1有望在医疗影像分析、自动驾驶、智能安防等领域发挥更大的作用。与此同时,开源生态的持续繁荣,也将为人工智能技术的发展提供更加广阔的平台。
VLM-R1不仅是一项技术突破,更是人工智能迈向多模态时代的重要里程碑。它的成功,让我们看到了未来智能世界的无限可能。






