CLIP:跨模态AI模型的技术革新
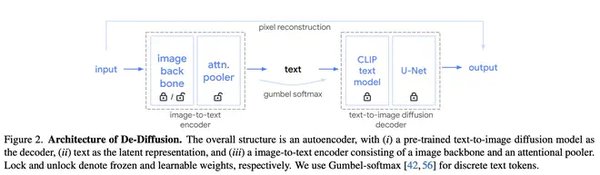
CLIP(Contrastive Language–Image Pretraining)是OpenAI开发的一款跨模态AI模型,它能够同时理解图像和文本,并且能够通过文本描述来生成相关图像。这一技术的出现,标志着人工智能在跨模态学习领域的一次重大突破。
技术原理
CLIP模型的核心在于其对比学习机制。通过大量的图像和文本对进行训练,CLIP能够学习到图像和文本之间的关联性。具体来说,模型会同时处理图像和文本数据,通过对比学习的方式,使得相似的图像和文本在嵌入空间中更加接近,而不相似的则更加远离。
应用场景
CLIP技术在多个领域展现了巨大的应用潜力:
-
图像搜索:CLIP能够通过文本描述快速找到相关图像,极大地提升了图像搜索的效率和准确性。
-
图像分类:CLIP可以理解复杂的文本描述,并将其应用于图像分类任务,使得分类结果更加精准。
-
跨模态推荐系统:CLIP能够结合用户的历史行为和文本描述,推荐更加符合用户需求的图像内容。
-
文本生成图像:CLIP能够根据文本描述生成相关图像,为创意设计和内容创作提供了新的工具。
未来展望
随着CLIP技术的不断发展和优化,未来可能会出现更多图像与文本结合的全新应用。例如,在医疗领域,CLIP可以帮助医生通过文本描述快速找到相关病例图像;在教育领域,CLIP可以根据学生的学习内容生成相关图像,提升学习效果。
技术挑战
尽管CLIP技术前景广阔,但仍面临一些挑战。例如,如何进一步提高模型的泛化能力,使其能够处理更加复杂和多样化的图像和文本数据;如何解决模型在处理多语言文本时的准确性问题等。
总结
CLIP作为一款跨模态AI模型,不仅在技术上实现了重大突破,也在多个应用场景中展现了巨大的潜力。随着技术的不断进步,CLIP有望推动图像与文本结合的全新应用,进一步改善计算机视觉领域的表现。未来,CLIP技术将在更多领域发挥重要作用,为人工智能的发展注入新的活力。



