2024年12月29日,研究人员推出了一款全新的编码器模型——ModernBERT。这一模型是对2018年发布的经典BERT模型的重大升级,旨在提高效率并支持更长的文本处理能力。ModernBERT的出现,标志着自然语言处理领域的一次重要突破。

长文本处理能力的提升
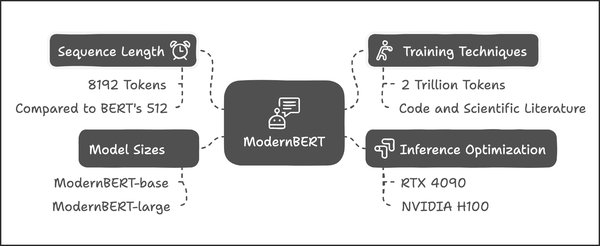
ModernBERT最引人注目的特性之一是其能够处理长达8192个Token的上下文。这一能力使得ModernBERT在处理长篇文章、复杂对话等场景时表现出色。相比之下,经典BERT模型在处理长文本时往往面临上下文截断的问题,而ModernBERT则通过优化模型结构,成功解决了这一难题。

强大的训练数据支持
ModernBERT使用了2万亿个Token进行训练,这一庞大的训练数据量确保了模型在各种自然语言任务中的泛化能力。通过对海量数据的学习,ModernBERT能够更好地理解语言的细微差别,从而在文本分类、问答系统、机器翻译等任务中表现出色。
两个版本满足不同需求
ModernBERT提供了两个版本,分别包含1.39亿和3.95亿参数。这两个版本的设计,旨在满足不同应用场景的需求。对于需要高效处理的任务,1.39亿参数的版本能够提供快速的推理速度;而对于需要更高精度的任务,3.95亿参数的版本则能够提供更强大的性能。
跨平台兼容性的重要性
在开发ModernBERT的过程中,研究人员也注意到了跨平台兼容性的重要性。正如在编程和文本处理中,换行符和回车符的使用在不同操作系统中的表现不同,ModernBERT在设计时也充分考虑了不同硬件和操作系统环境下的兼容性,确保模型能够在各种平台上稳定运行。
实际应用中的表现
在实际应用中,ModernBERT已经展现出了其强大的潜力。无论是在文本生成、情感分析,还是在复杂的对话系统中,ModernBERT都表现出了优异的性能。其高效的长文本处理能力,使得它在处理长篇文档、学术论文等场景时尤为突出。
未来展望
随着技术的不断发展,ModernBERT将继续优化其模型结构,进一步提升其处理能力和效率。研究人员也计划在未来推出更多版本的ModernBERT,以满足不同应用场景的需求。可以预见,ModernBERT将在自然语言处理领域发挥越来越重要的作用。
ModernBERT的推出,不仅是对经典BERT模型的重大升级,更是自然语言处理领域的一次革命性突破。通过提升长文本处理能力和跨平台兼容性,ModernBERT为未来的研究和应用提供了强大的支持。






