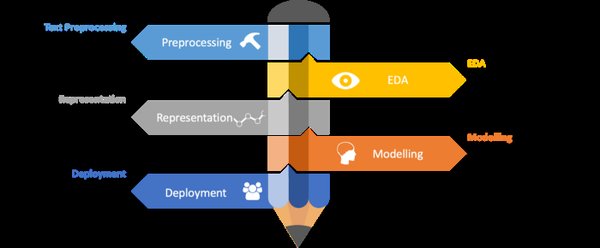
NLP预处理技术的重要性
自然语言处理(NLP)作为人工智能领域的核心技术之一,其预处理环节是确保后续任务高效准确的基础。NLP预处理技术包括文本清洗、分词、词性标注、句法分析等多个环节,每一个环节都对最终的处理结果有着重要影响。
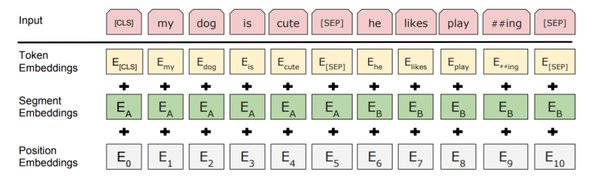
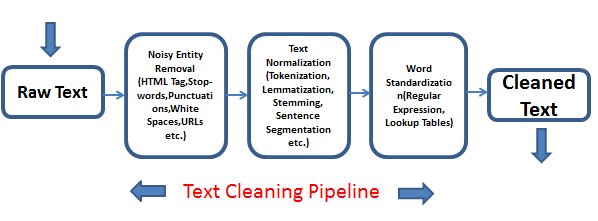
文本分类的实际应用
文本分类是NLP中的基础任务,广泛应用于垃圾邮件检测、新闻分类等场景。以IMDB数据集为例,通过DeepSeek框架,我们可以快速构建和训练一个基于BERT的文本分类模型。具体步骤包括数据集准备、模型构建和模型评估,最终在测试集上验证模型的准确率。
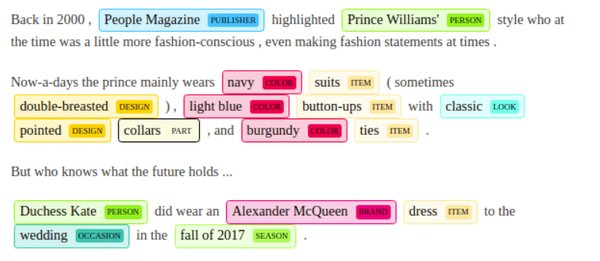
命名实体识别(NER)的技术细节
命名实体识别(NER)用于识别文本中的具名实体,如人名、地名、组织名等。以CoNLL-2003数据集为例,利用DeepSeek框架构建一个基于BERT和CRF的NER模型,可以有效提高实体识别的准确性。模型训练完成后,同样需要在测试集上进行评估,以确保其性能。
情感分析的技术实现
情感分析任务是NLP中最常见的任务之一,目的是分析文本的情感倾向。通过DeepSeek框架,我们可以使用深度神经网络或LSTM/RNN进行文本序列建模,构建情感分析模型。以Sentiment140数据集为例,模型训练和评估的过程与文本分类和NER类似,最终在测试集上验证模型的准确率。
高级分词技术的探索
分词是NLP预处理的重要环节,传统分词方法在处理复杂文本时往往力不从心。高级分词技术,如子词分割,可以有效解决这一问题。通过构建一个子词词汇表,结合正则表达式和贪心算法,可以实现对长词的有效分割,提高分词的准确性和效率。
OCR与NLP融合的前景
OCR(光学字符识别)与NLP技术的结合为表格内容的理解与分析带来了新的机遇和挑战。通过智能识别、语义理解和数据分析,我们可以实现对表格内容的高效处理和深入挖掘。未来,随着技术的不断进步,OCR与NLP的融合将在更多领域发挥重要作用,推动各行各业的智能化转型。
总结
NLP预处理技术在自然语言处理任务中扮演着至关重要的角色。从基础的文本分类、命名实体识别、情感分析,到高级的分词技术,再到OCR与NLP的融合,每一个环节都充满了挑战和机遇。通过不断探索和创新,我们可以进一步提升NLP技术的应用效果,推动人工智能领域的持续发展。



