视觉-语言导航(VLN)作为具身智能领域的前沿研究方向,旨在开发能够根据自然语言指令在物理环境中导航的智能体。然而,传统的VLN系统在模拟环境中表现优异,却在现实场景中面临巨大挑战。NeurIPS 2024精选论文《人类感知视觉语言导航:具有动态人机交互的导航任务》通过引入动态人机交互,为这一领域带来了突破性进展。
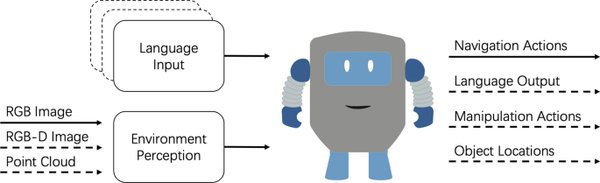
动态人机交互:填补现实与模拟的鸿沟
传统VLN系统通常依赖于静态环境和全景视图,这些假设在现实场景中难以成立。为了缩短模拟与现实之间的差距,研究团队提出了一种非静态的导航任务,将人类活动纳入导航场景。通过创建人类感知3D(HA3D)模拟器,研究团队开发了一个包含145个人类活动描述和435个三维人体动作模型的数据集,扩展了Room-to-Room(R2R)数据集,并建立了人类感知的R2R数据集(HA-R2R)。
这种动态人机交互的设计使VLN系统能够更好地适应现实世界的复杂性和不可预测性,为具身智能的实际应用奠定了坚实基础。
新型导航agent:VLN-CM与VLN-DT
研究团队开发了两种新型导航agent:
-
VLN-CM:专家监督的跨模态agent,通过多模态信息融合实现精准导航。
-
VLN-DT:非专家监督的决策agent,通过随机轨迹训练实现与专家监督方法相当的性能。
在真实世界中的测试结果表明,VLN-DT在仅使用随机轨迹进行训练的情况下,依然能够实现高效的导航任务。这一成果为未来开发更灵活、适应性更强的导航系统提供了重要参考。
多专家讨论框架:提升导航性能的新范式
另一项相关研究提出了“多专家讨论框架”,通过引入多个领域专家(如指令分析专家、视觉感知专家、完成度估计专家等),导航智能体可以在每一步行动前与专家进行讨论,以收集必要的信息。这种框架不仅提升了导航系统的性能,还增强了其在复杂环境中的鲁棒性。
未来展望:具身智能的现实应用
随着动态人机交互和多专家讨论框架的引入,VLN系统在现实场景中的应用潜力得到了显著提升。未来的研究方向包括:
-
进一步优化HA3D模拟器,以更真实地模拟人类活动。
-
探索多模态信息的深度融合,提高导航系统的感知与决策能力。
-
开发更灵活的导航agent,使其能够适应更多样化的现实场景。
结语
人类感知视觉语言导航的研究为具身智能领域开辟了新的方向。通过动态人机交互和多专家讨论框架,VLN系统在现实场景中的性能得到了显著提升。这一成果不仅填补了真实世界导航研究的缺失,也为未来具身智能的实际应用提供了重要基础。











