在自然语言处理(NLP)领域,BART模型(Bidirectional and Auto-Regressive Transformer)凭借其独特的架构和强大的性能,成为了文本生成、机器翻译等任务中的佼佼者。本文将深入探讨BART模型的架构特点、应用场景以及未来发展方向。

BART模型的架构特点
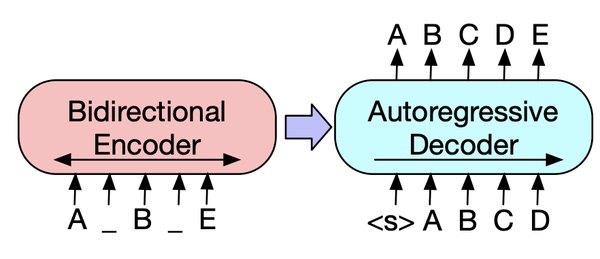
BART模型结合了BERT的双向编码器特征和GPT的自回归解码器特征,使其在序列生成任务中表现出色。其核心架构包括:
-
双向编码器:BART模型的双向编码器能够同时处理输入序列的前后文信息,从而更好地理解上下文关系。
-
自回归解码器:自回归解码器则允许模型在生成文本时逐步预测下一个词,确保生成的文本连贯且符合上下文。
这种结合了双向编码和自回归解码的架构,使BART模型在文本生成、机器翻译等任务中表现出色。

BART模型的应用场景
BART模型在多个NLP任务中展现出了卓越的性能,主要包括:
-
文本生成:BART模型能够根据给定的上下文生成连贯且符合逻辑的文本,广泛应用于新闻摘要、故事生成等场景。
-
机器翻译:在机器翻译任务中,BART模型通过双向编码器捕捉源语言和目标语言之间的语义关系,结合自回归解码器生成流畅的翻译结果。
-
文本摘要:BART模型能够对长篇文章进行有效摘要,提取关键信息并生成简洁的摘要文本。

BART模型的未来发展方向
随着NLP技术的不断进步,BART模型在未来有望在以下方面取得进一步发展:
-
多模态支持:将BART模型扩展到多模态领域,使其能够处理图像、音频等多种数据模态,进一步提升其应用范围。
-
模型压缩与优化:通过模型压缩技术,如剪枝、量化和知识蒸馏,优化BART模型的计算效率,使其更适用于资源受限的环境。
-
持续学习:引入持续学习技术,使BART模型能够在新任务中不断学习和适应,避免灾难性遗忘,提升模型的长期性能。
结论
BART模型凭借其独特的架构和强大的性能,在自然语言处理领域展现出了广泛的应用前景。未来,随着技术的不断进步,BART模型有望在多模态支持、模型压缩与优化、持续学习等方面取得新的突破,进一步推动NLP技术的发展。





