在AI领域,大规模模型的训练一直是一个巨大的挑战。随着模型规模的不断增长,计算资源的需求也呈指数级上升。DeepSeek在最近的“开源周”中,发布了多项开源技术和系统,其中优化并行策略(Optimized Parallelism Strategies)成为焦点。这些策略通过创新的算法和工具,显著提升了AI模型的训练效率,为开发者提供了强大的支持。
为什么优化并行策略如此重要?
训练大规模AI模型时,传统的并行方法往往存在资源浪费和效率低下的问题。例如,在多个GPU上训练模型时,某些GPU可能会因为等待其他GPU的计算结果而处于闲置状态,这种现象被称为“气泡”(bubbles)。这不仅浪费了计算资源,还延长了训练时间。
DeepSeek的优化并行策略通过重叠计算与通信、动态负载均衡等技术,解决了这些问题。这些策略不仅提高了资源利用率,还显著缩短了训练时间,为开发者节省了大量成本。
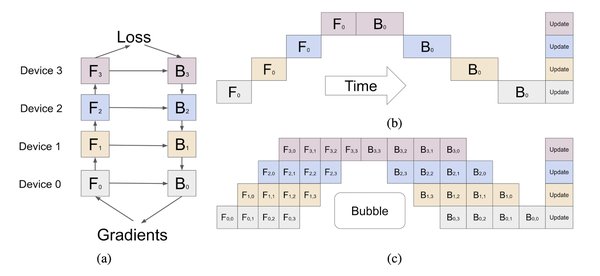
DualPipe:重新定义管道并行
DeepSeek推出的DualPipe是一种双向管道并行算法,旨在消除传统管道并行中的“气泡”问题。通过让计算和通信同时进行,DualPipe确保了所有GPU都处于忙碌状态,从而最大限度地提高了效率。
此外,DualPipe还解决了跨节点通信的瓶颈问题。在分布式训练中,不同机器之间的数据传输往往会成为性能瓶颈。DualPipe通过在计算的同时进行通信,大幅减少了等待时间,使得大规模模型的训练更加流畅。

EPLB:Mixture-of-Experts模型的负载均衡利器
对于Mixture-of-Experts(MoE)模型,负载均衡是一个关键问题。MoE模型通过门控机制选择不同的专家处理输入数据,但某些专家可能会被过度使用,而其他专家则处于闲置状态,导致资源浪费。
DeepSeek的EPLB(Expert-Parallel Load Balancer)通过动态调整专家的分布,确保了所有GPU的负载均衡。这不仅提高了训练效率,还减少了瓶颈问题,使得MoE模型的训练更加高效。
DeepSeek的生态系统:从计算到通信的全面优化
DeepSeek不仅仅关注单一的技术创新,而是构建了一个完整的生态系统。从FlashMLA加速解码到DeepGEMM优化矩阵运算,再到DualPipe和EPLB的并行与负载均衡,这些工具共同构成了一个高效的AI训练框架。
这种全面的优化策略使得开发者能够在不同的场景中灵活应用这些工具,无论是训练小型模型还是大规模分布式模型,都能显著提升性能。
开源的力量:推动AI技术的普及与创新
DeepSeek的开源策略不仅为开发者提供了强大的工具,还推动了AI技术的普及。通过将这些优化并行策略开源,DeepSeek降低了进入AI领域的门槛,使得更多的小型团队和独立开发者能够参与到大模型的研究与开发中。
此外,DeepSeek还公开了性能分析数据,帮助开发者更好地理解这些策略的实现细节。这些数据通过PyTorch Profiler捕获,开发者可以轻松地在浏览器中可视化,从而更高效地优化自己的训练流程。
未来展望:AI效率的新时代
DeepSeek的优化并行策略标志着AI训练效率的新时代。随着这些工具的广泛应用,AI模型的训练时间将从数月缩短到数周甚至数天。这不仅加速了AI技术的发展,还为解决复杂的社会问题(如气候变化、医疗健康等)提供了强大的支持。
DeepSeek的开源周只是一个开始,未来还将有更多的创新工具和技术问世。开发者们已经可以开始将这些工具集成到自己的项目中,探索AI技术的无限可能。
结语
DeepSeek通过优化并行策略,为AI训练效率带来了革命性的提升。DualPipe和EPLB等开源工具不仅解决了大规模模型训练中的关键问题,还为开发者提供了灵活、高效的解决方案。在开源的力量下,AI技术的未来将更加光明。
你是否已经准备好将这些工具应用到自己的项目中?加入DeepSeek的开源社区,一起推动AI技术的创新与发展!









