DeepSeek-R1:低成本高性能AI的崛起
近年来,随着大模型技术的快速发展,AI领域的竞争愈发激烈。中国深度求索(DeepSeek)发布的DeepSeek-R1开源大模型以其低成本高性能的特点,成为全球AI领域的热门话题。DeepSeek-R1不仅展示了中国在AI技术上的创新能力,也为大模型的普及和商业化提供了新的可能性。

MOE技术:DeepSeek-R1的核心优势
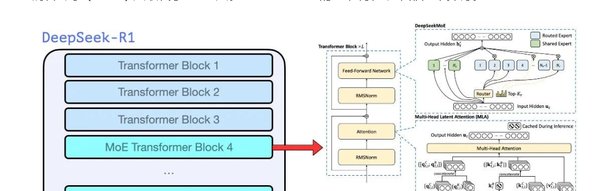
DeepSeek-R1的成功离不开其核心架构——MOE(Mixture of Experts,专家混合模型)。MOE通过将大模型分割为多个专家模块,仅在需要时激活相关模块,从而大幅降低了计算资源消耗。这种稀疏激活策略使得DeepSeek-R1在保持高性能的同时,显著减少了训练和推理的成本。
此外,DeepSeek还优化了MLA(Memory-Level Attention)和MTP(Multi-Token Prediction)技术,进一步提升了模型的效率和性能。MLA通过压缩输入数据,将计算所需的显存容量降低了一半,而MTP则通过一次性预测多个token,提高了学习效率。
开源策略:推动AI技术普及
DeepSeek-R1的开源策略是其另一大亮点。尽管并非完全开源,但其部分权重和训练方法已免费公开,吸引了大量开发者和企业参与。这种“半开源”模式不仅加速了技术的普及,也为AI生态链注入了新的活力。
然而,开源模型也面临诸多挑战。例如,如何激励社区贡献、如何优化模型压缩技术、如何确保行业数据共享与安全标准等,都是需要解决的问题。

DeepEP:MOE优化的新里程碑
为了进一步提升MOE模型的性能,深度求索推出了DeepEP(Expert Parallelism Communication Library)。DeepEP专为MOE模型的分布式训练和推理设计,通过优化GPU间通信机制,显著提高了模型的训练效率和推理速度。
DeepEP支持NVLink和RDMA技术,能够在多节点、多GPU环境下实现高效通信。其低延迟计算核心特别适用于实时推理任务,为MOE模型的应用场景提供了更多可能性。
开源模型重塑AI生态链
DeepSeek-R1的成功标志着开源模型在AI领域的崛起。通过低成本高性能的技术路径,开源模型不仅降低了企业的技术门槛,也为AI应用的多样化提供了基础。
未来,随着更多开源模型的涌现,AI生态链将迎来新的变革。无论是技术开发者还是企业用户,都将在这场变革中找到新的机遇与挑战。
结语
DeepSeek-R1以其低成本高性能的特点,为AI大模型的发展树立了新的标杆。其MOE技术和开源策略不仅推动了技术的普及,也为AI生态链带来了新的商业潜力。尽管面临诸多挑战,但开源模型的未来无疑充满希望。


.png)



