近年来,AI领域的发展一直围绕着“缩放定律”(Scaling Laws)展开,即通过增加模型参数、计算资源和数据量来提升性能。然而,DeepSeek R1模型的横空出世,彻底颠覆了这一传统认知。
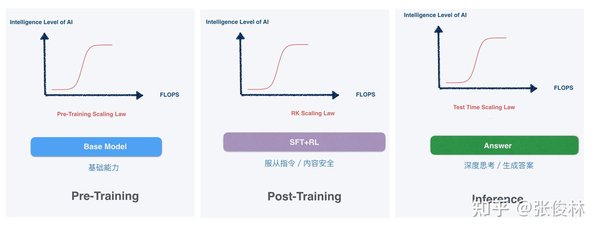
传统缩放定律的挑战
传统AI缩放定律认为,模型的性能与参数数量、计算资源和数据量呈正相关。OpenAI的GPT系列模型正是这一理论的代表,GPT-4的训练成本高达1亿美元以上。然而,DeepSeek R1仅以560万美元的训练成本,实现了与GPT-4相当的性能,这一突破引发了市场的广泛关注。
DeepSeek R1的成功不仅体现在成本效益上,更在于其对缩放定律的重新诠释。通过优化训练策略和模型架构,DeepSeek证明,高性价比的AI模型同样可以实现卓越性能。
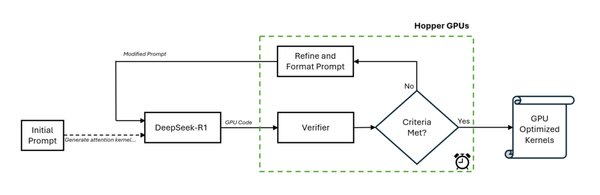
高性价比训练的核心创新
DeepSeek R1的成功得益于多项技术创新:
-
自适应缩放策略:根据数据质量动态调整模型规模和训练策略,最大化学习效率。
-
蒸馏技术:通过将大模型的知识迁移到小模型,显著提升小模型的性能。
-
高质量数据筛选:优先使用高质量数据集,减少噪声数据的干扰。
这些创新使得DeepSeek R1在数学推理、编程等任务中表现优异,甚至接近更大规模模型的能力。


对AI基建产业链的影响
DeepSeek R1的出现对AI基建产业链产生了深远影响:
-
GPU市场:Nvidia股价一度下跌17%,市场担忧高性价比模型将减少对高性能GPU的需求。
-
数据中心:随着模型训练成本的降低,数据中心的建设需求可能从规模扩张转向效率提升。
-
光模块与交换机:AI基建的高效化将推动相关硬件技术的创新与优化。
未来趋势:从规模到效率
DeepSeek R1的成功标志着AI研究从“规模至上”向“效率优先”的转变。未来的AI模型将更加注重:
-
任务适配性:根据任务需求优化模型架构,而非盲目扩大规模。
-
持续学习:通过动态更新机制,提升模型对最新知识的理解能力。
-
多语言支持:扩展训练数据的语言多样性,提升模型的全球适用性。
结论
DeepSeek R1不仅是一次技术突破,更是对AI发展路径的重新定义。它证明,高性价比的AI模型同样可以引领行业变革。随着AI研究从规模竞赛转向效率优化,未来的AI技术将更加智能、高效且可持续。
在这场AI马拉松中,DeepSeek已经迈出了关键一步,而真正的竞赛才刚刚开始。





